R语言-数据抽取(一)
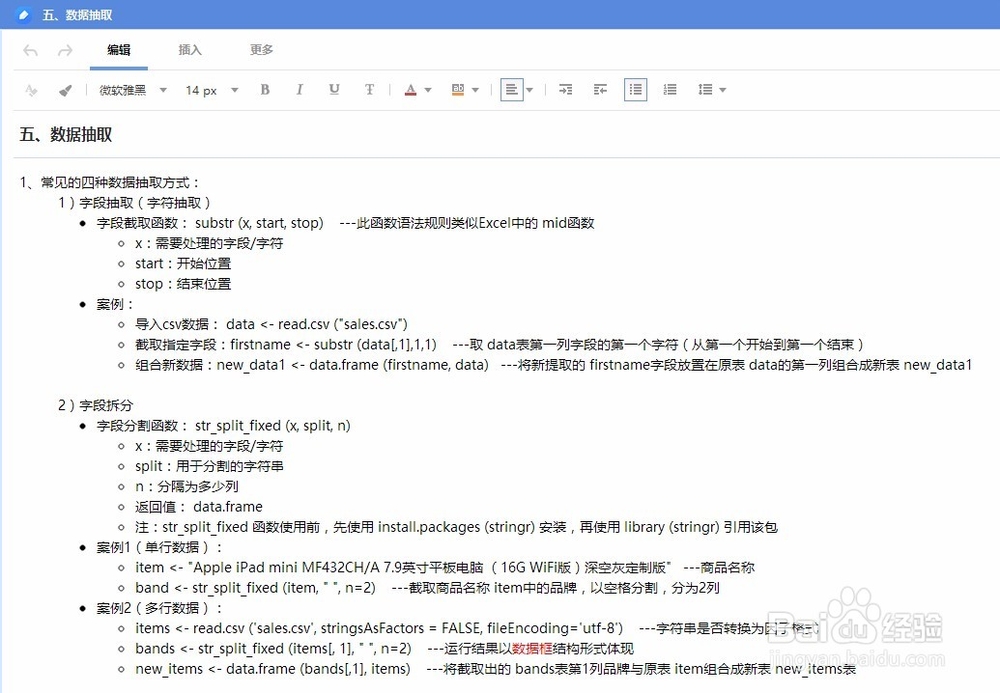
1、常见的四种数据抽取方式:1)字段抽取(字符抽取)字段截取函数: substr (x, start, stop) ---此函数语法规则类似Excel中的 mid函数x:需要处理的字段/字符start:开始位置stop:结束位置案例:导入csv数据: data <- read.csv ("sales.csv")截取指定字段:firstname <- substr (data[,1],1,1) ---取 data表第一列字段的第一个字符(从第一个开始到第一个结束)组合新数据:new_data1 <- data.frame (firstname, data) ---将新提取的 firstname字段放置在原表 data的第一列组合成新表 new_data1
2、2)字目愿硅囫段拆分字段分割函数: str_split_fixed (x, split, n)x:需要处理的字段/字符split:用于分割的字符串n:分隔为多少列返回值: data.frame注:str_split_fixed 函数使用前,先使用 install.packages (stringr) 安装,再使用 library(stringr)引用该包案例1(单行数据):item <- "Apple iPad mini MF432CH/A 7.9英寸平板电脑 (16G WiFi版)深空灰定制版" ---商品名称band <- str_split_fixed (item, " ", n=2) ---截取商品名称 item中的品牌,以空格分割,分为2列案例2(多行数据):items <- read.csv ('sales.csv', stringsAsFactors = FALSE, fileEncoding='utf-8') ---字符串是否转换为因子格式bands <- str_split_fixed (items[, 1], " ", n=2) ---运行结果以数据框结构形式体现new_items <- data.frame (bands[,1], items) ---将截取出的 bands表第1列品牌与原表 item组合成新表 new_items表