搭建 Hadoop 群集
共7大步骤
更改所有节点的机器名
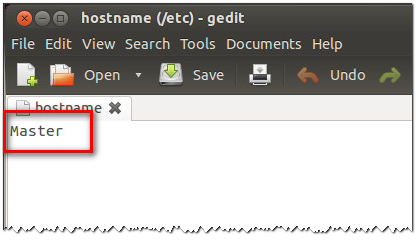
1、为方便操作,更改机器名,使群集内的机器名分别为Master、Slave1、Slave2、Slave3、Slave4、Slave5、Slave6……
2、具体修改方法:在Ubuntu的终端中执行下列命令,更换原有文件内容即可(图),修改后重启操作系统方可生效。sudo gedit /etc/hostname
修改hosts文件
1、节点规磷挎菪闲划与hosts文件修改。在这里,我使用了1台Master和7台Slave,并记录了8台虚拟机对应的IP。将虚拟机名称和对应的IP写入所有节点机器(包括Master和Slave)的hosts文件,使用如下命令sudo gedit /etc/hosts
2、添加如图所示的内容并保存。

3、补充说明:如果hosts文件中有“127.0.1.1 Ubuntu”行,则应该删除,因为前面已经修改了机器名,机器名已不再是“Ubuntu”,若不删除,在执行带有sudo的命令后,会得到内容为“unable to resolve host xxx”的警告提示。
MapReduce配置
1、分别配置$HADOOP_HOME/conf目录下的core-site.xml、hdfs-site.xml和mapred-site.xml文件
2、修改core-site.xml

3、修改hdfs-site.xml

4、修改mapred-site.xml

Hadoop群集主从设置
1、主动设置即设置主节点和从节点,分别配置$HADOOP_HOME/conf目录下的masters和slaves文件
同步配置
1、Hadoop集群的所有机器的配置应该保持一致,因此在配置完master后,应将配置文件同步到集群的其它服务器
2、失败的方法:通过hadoop-env.sh同步
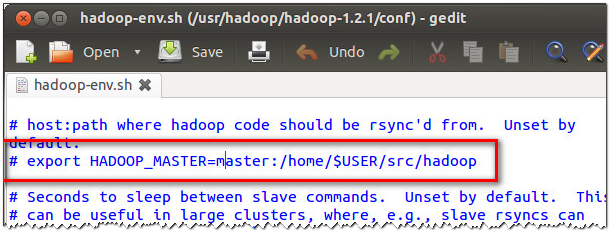
3、注意这是失败的方法
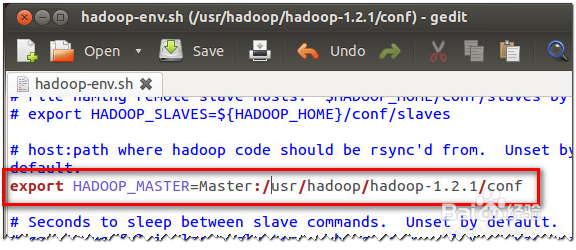
4、成功的方法:使用scp命令
5、在机器Master的终端中,依次执行下列7行命令同步MapReduce设置

同步时间
1、在大部分网络教程中没有看到这一步,但我还是将群集中所有的节点的系统时间逐一与网络同步,从而方便查看不同节点上Hadoop的日志并对比。
Hadoop群集启动与关闭
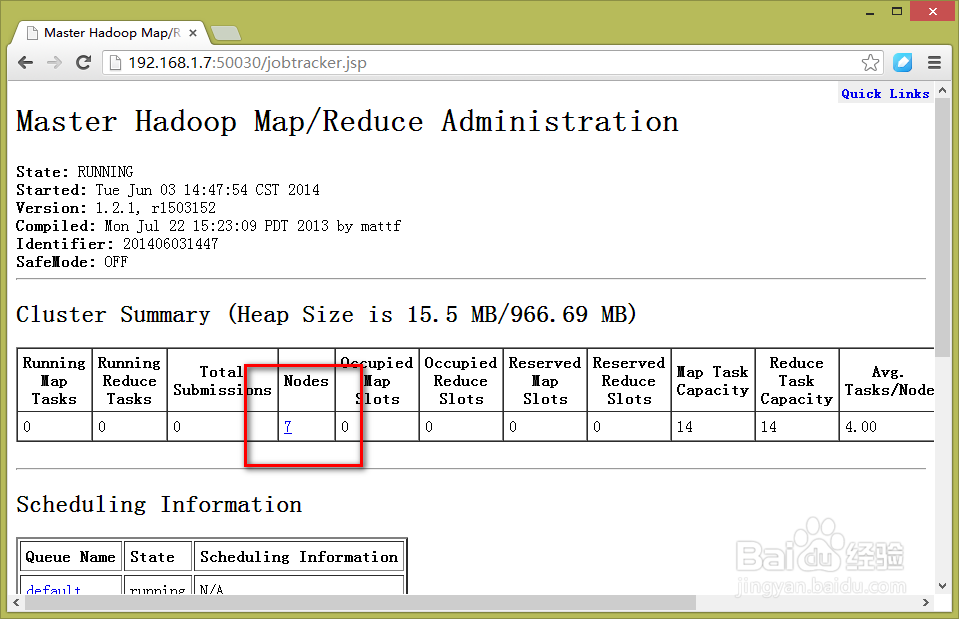
1、HDFS的状态
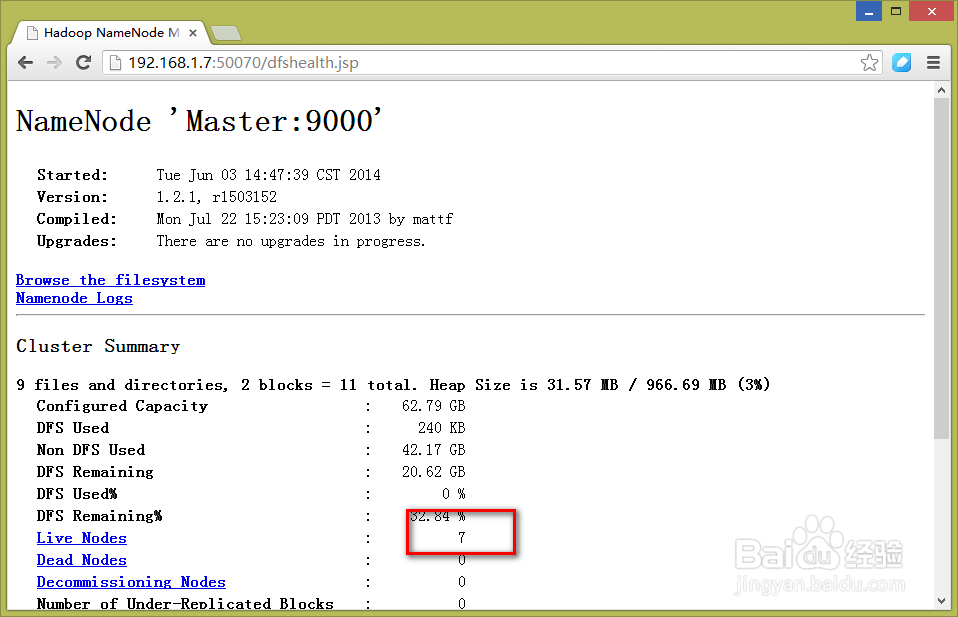
2、MapReduce的状态