怎么制作一个决策树分类器?
1、加载模块。
# -*- coding: utf-8 -*-
import numpy as np
import scipy as sp
from sklearn import tree
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
个别模块被别的东西取缔了,python给了我们一个提示。
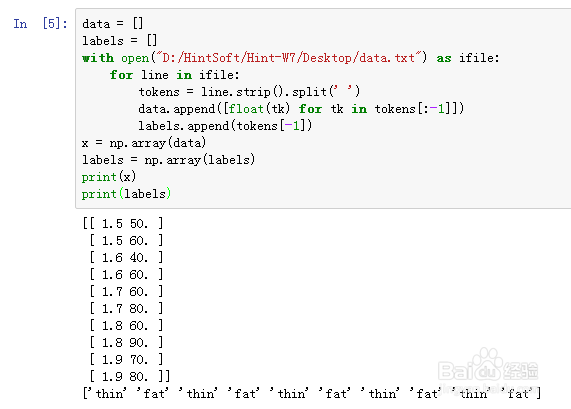
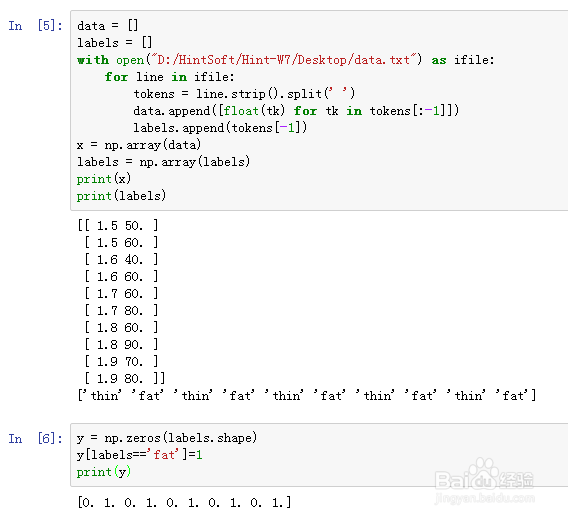
2、把txt文档里面的数据读取出来:
data = []
labels = []
with open("D:/HintSoft/Hint-W7/Desktop/data.txt") as ifile:
for line in ifile:
tokens = line.strip().split(' ')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
x = np.array(data)
labels = np.array(labels)
print(x)
print(labels)
3、把瘦用0代替,把胖用1代替:
y = np.zeros(labels.shape)
y[labels=='fat']=1
4、构造训练数据集和测试集:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
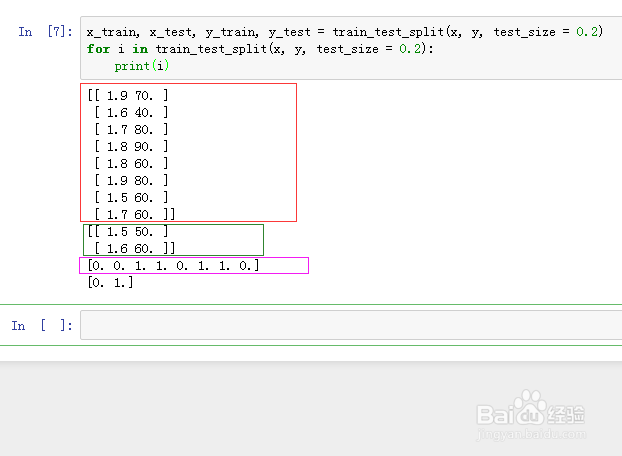
5、构造一个未训练的树状分类器:
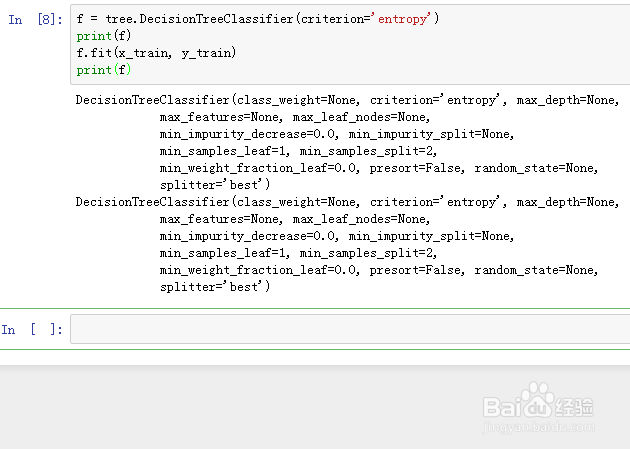
f = tree.DecisionTreeClassifier(criterion='entropy')
用训练集来训练这个分类器:
f.fit(x_train, y_train)
训练的过程,就是拟合。
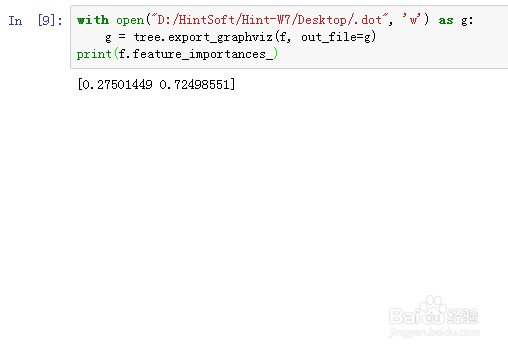
6、把训练的树状分类器保存下来:
with open("D:/HintSoft/Hint-W7/Desktop/.dot", 'w') as g:
g = tree.export_graphviz(f, out_file=g)
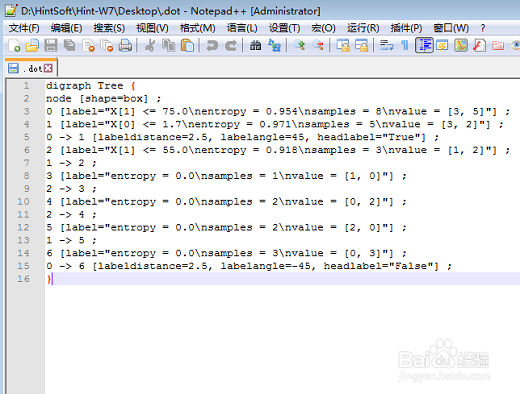
打开dot文件,可以看到这个决策树的各参数。
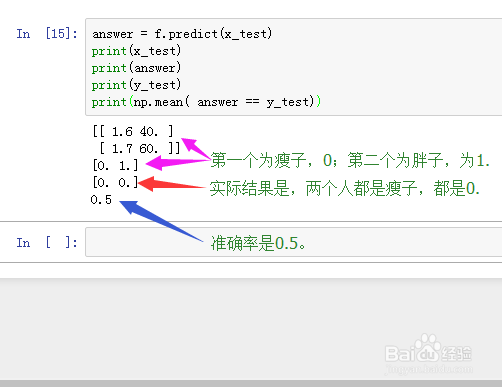
7、用测试集对f进行测试:
answer = f.predict(x_test)
print(x_test)
print(answer)
print(y_test)
print(np.mean( answer == y_test))