java文件操作之字符流
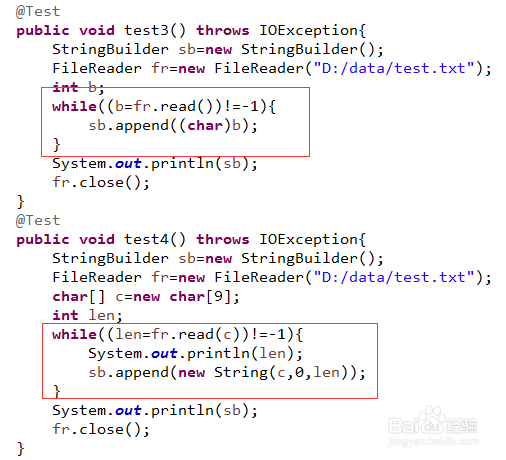
1、先来看一眼,源码对FileReader的解释: 读取字符文件的方便类。类的构造方法,使用默认的编码格式和默认字节缓冲区大小。 你可以在FileInputStream上构造一个InputStreamReader,去定义这些值。 FileReader的意义在于读取字符流。如果要读取原生的字节,请考虑使用FileInputStream。

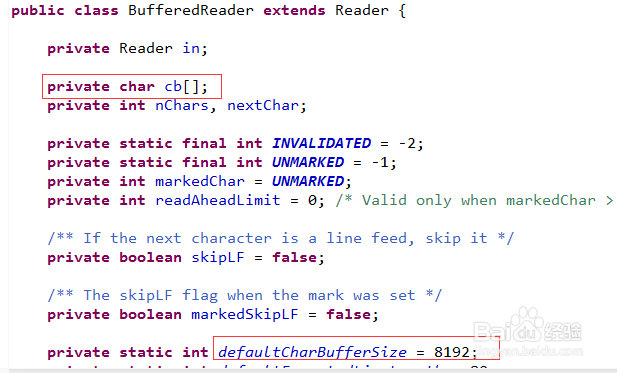
2、再来看一眼,源码对BufferedReader的解释:从字符输入流中读取文本,提供了字符缓存螃赎瘵簟池,去孕驷巴墟高效的按字符、数组或者行读取数据。缓存池的大小应该被定义,或者使用默认的大小8192.对大部分情况来说,默认的大小已经足够大了。使用BufferedReader,会缓存特定文件的输入。没有缓存池,调用read和readLine方法会导致直接去文件中读取,然后转换成字符,然后返回,这种方式效率很低。


3、看到这里应该明白这两者的最大的区别,就是BufferedReader使用了一个足够大的缓秽颢擤崮存池。打个比方,你要村民吃魇堀绉珀河水,可以每次吃的时候去河边提一桶,但是发现一桶水不够用,所以又跑过来提了好几次。其实也可以这么干买一个大水缸,用三轮车运过来,放满水,然后运回去吃一个星期。例子有点粗糙,其实就是这个意思。按照这个思路,按道理来说第一次读的时候,应该尽可能的把缓存池读满,然后从缓存池中取数据,当数据块取完的时候再从文件六中读到缓存池,,,,循环往复按照这个想法,继续去看源码
4、先来介绍一下BufferedReader的三个方便的方法BufferedReader.read():每次从缓存中读取一个字符BufferedReader.read(char[] c):每次从缓存中读取c.length个字符BufferedReader.readLine():每次读取一行数据
5、通过BufferedReader.read()来分析,找到他的大水缸。编写测试类,从文件中读取数据,发现可以正常读取。
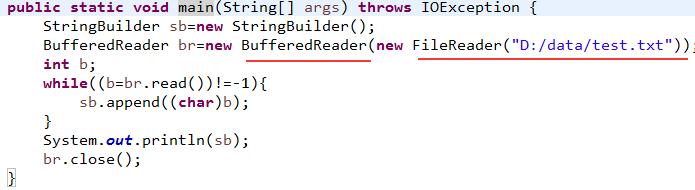
6、且看其构造方法,传入一个Reader流,其实调用的是BufferedReader(Reader in, int sz),这个方法创建了一个字符数组cb,默认大小defaultCharBufferSize=8192,这个就是缓存池,我们的大水缸。
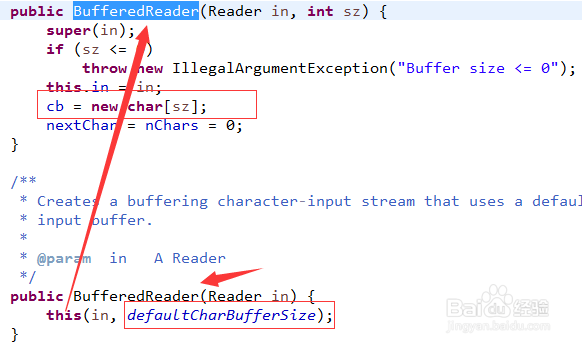
7、然后在看read方法,调用的是BufferedReader的read()方法,可以看到其取数据是从cb中取得。但是在第一次调用的时候回进入fill()方法。
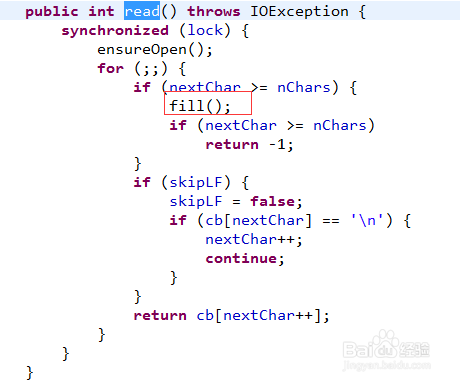
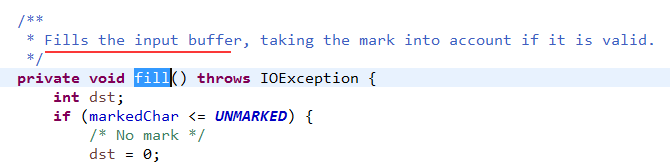
8、再来看fill方法的方法注释:填充缓存池。并且其第一次会调用:此方法的最下面,dst刚开始是0,所以会从FileReader文件流中尽可能的去读取数据,存储到cb中,这一步第一次装好了缓存池。说道这里就清楚了其缓存池的原理了。
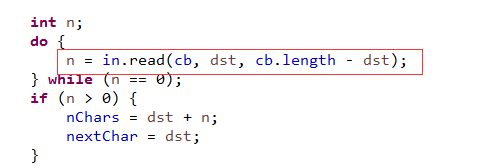
9、再来看其另外两个方法的使用,如下图:BufferedReader.read(char[] c):BufferedReader.readLine()
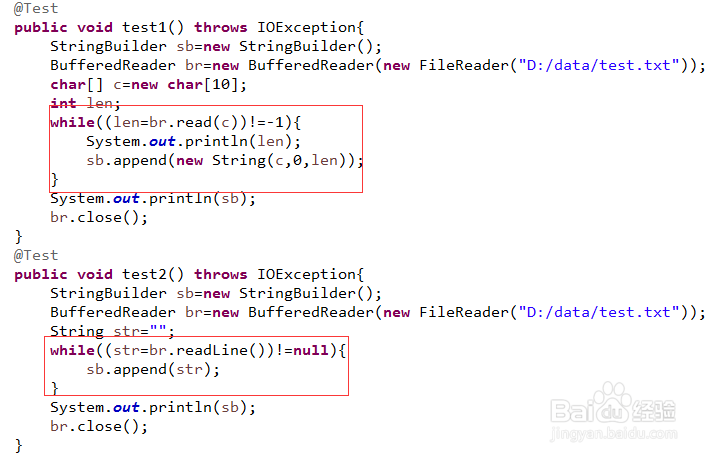
10、再来看一眼,FileReader的方法主要有两个FileReader.read():从文件流中读取一个字符FileReader.read(char[] c):从文件流中读取c.length个字符。使用方式如下图,基本和BufferedReader中这两个方法一样,只不过,没有使用缓存池技术。