直接从docx文件中提取文字和图片
1、首先,我们有一个docx文档如图所示。文档内有文字,图片等。下面说不使用Word软件就直接提取内容的办法,这样也方便程序控制。
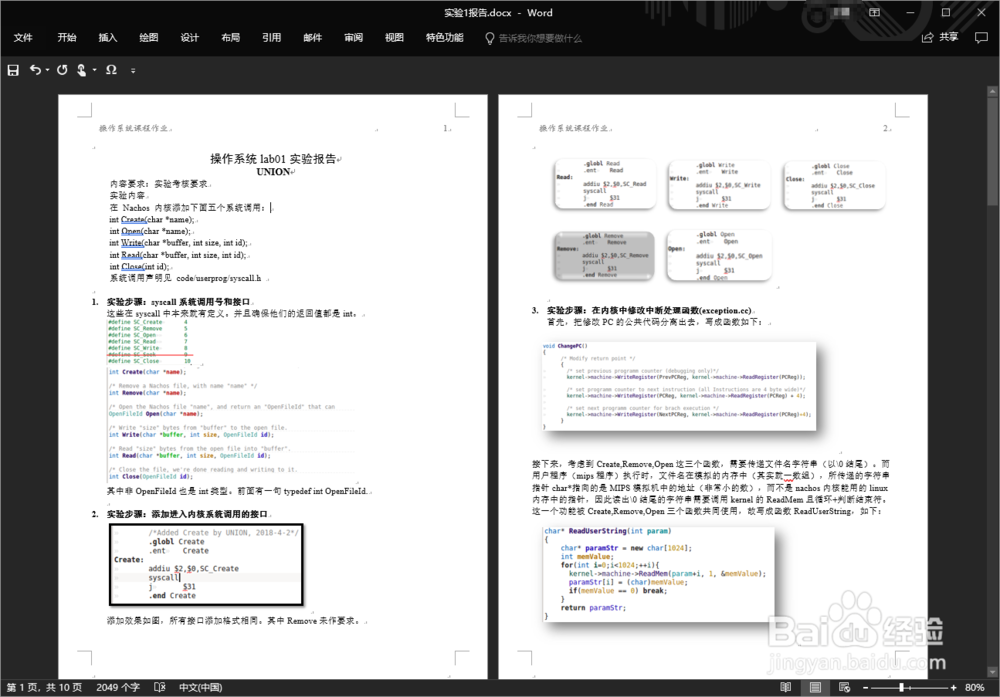
2、和以前的二进制doc不同,docx本质是以一些xml文件和资源/媒体文件打包压缩而成,是zip类型。我们修改docx后缀为zip后缀,解压缩,就可以看到里边的文件。

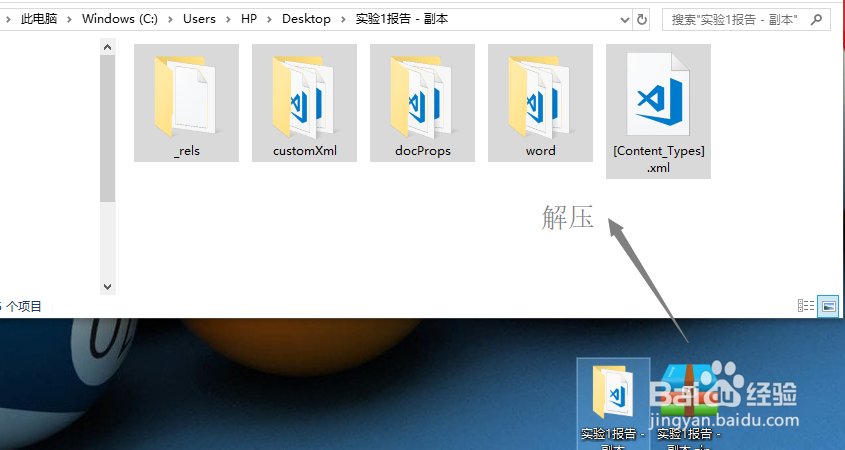
3、文档的图片/文字/页眉/页脚/脚注等,都在word文件夹下。打开这个文件夹。
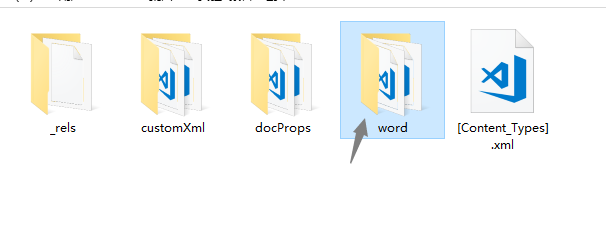
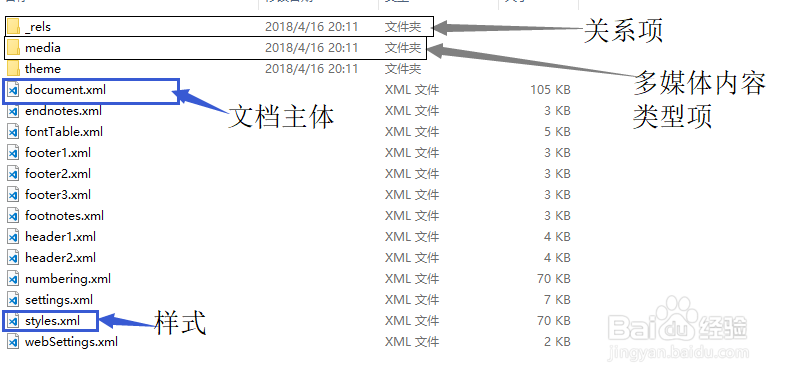
4、在word文件夹内,_rels文件夹是描述关系的xml文件,比如描述资源id和具体文本图片等等之间的关系。media是多媒体内容。文档中的图片资翮堠江辰源会保存在此。document.xml是文档主体,我们能看到xml格式保存的文档正文。style.xml是一些样式定义。
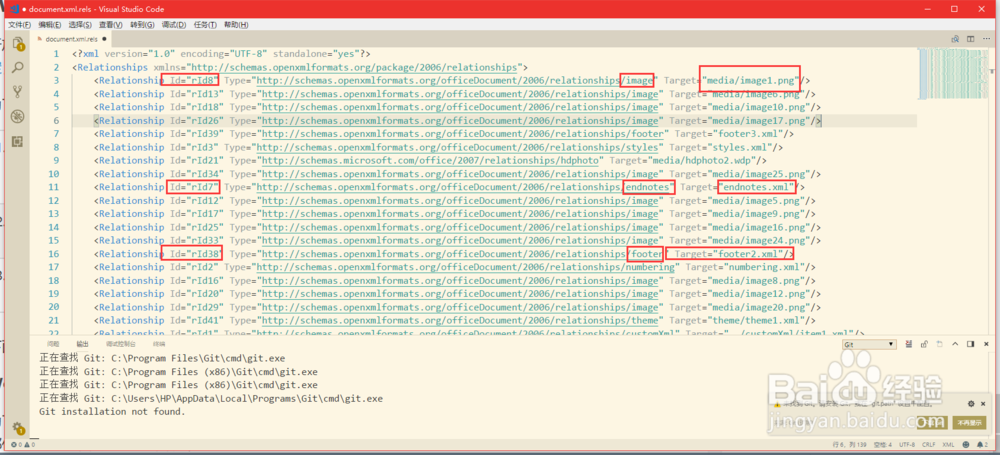
5、打开_rels文件夹,并打开document.xml.rels文件,可以看到如图内容,是一些资源id,资源类型,资源所在位置(文件名)的项。如有需要我们,可以修改它们。
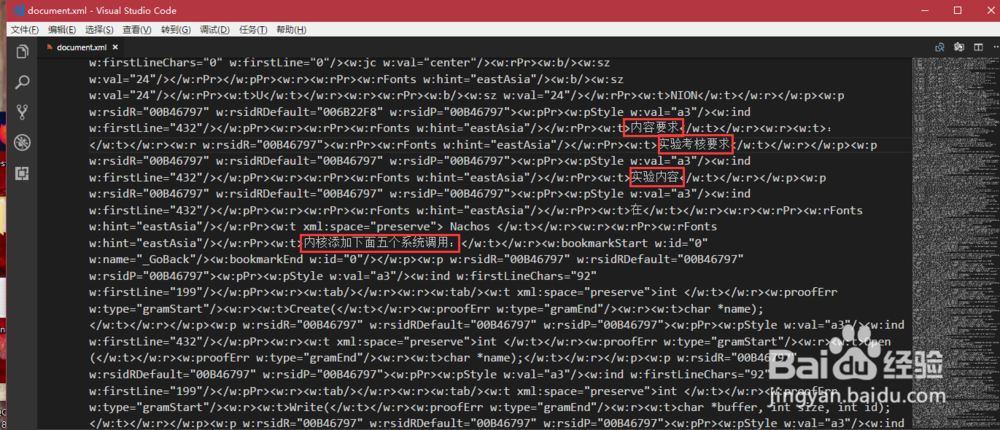
6、打开document.xml文档主体,可以看到在成对的<w:t>和</w:t>之间,有文档的文本内容。
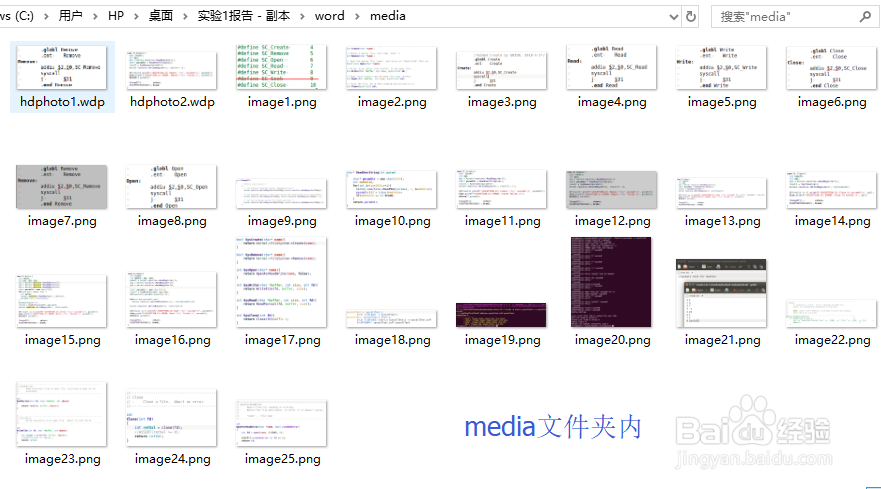
7、打开media文件夹,可以看到word中的图片以文件形式在此。如图,比如一些命名为image*.png的图片。如有需要我们可以替换这些文件,word文档中的对应图片还会在原来位置按照原来的宽高拉伸。
8、关于document.xml主体文件的搜索,首先我们可以使用xml解析程序/解析函数,比如使用MMA中的Import导入xml中的文本项。
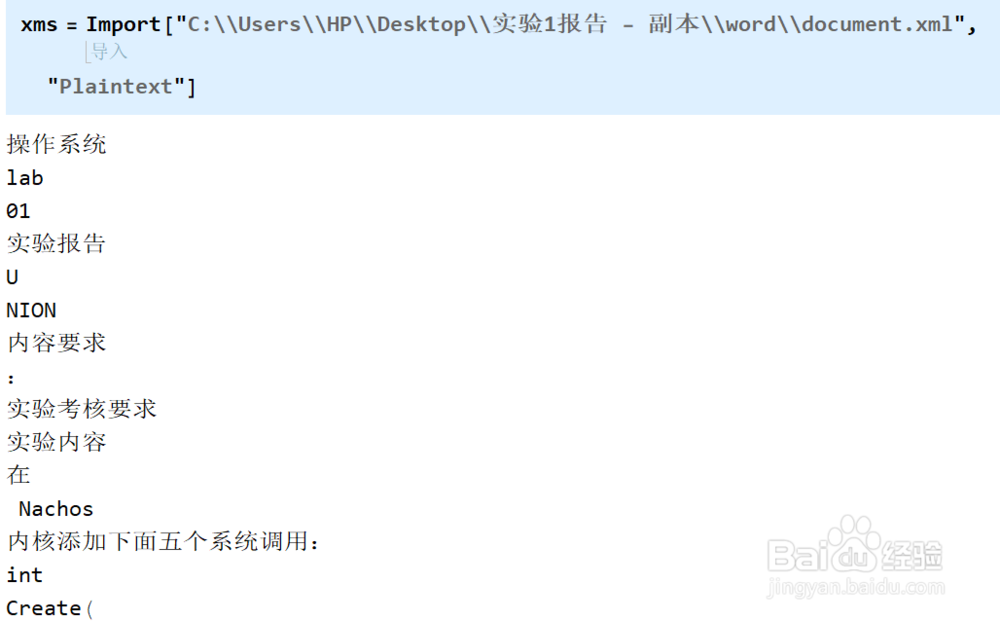
9、当然,我们也可以使用正则表达式匹配。如图菰灞巴静举一个简单例子,在MMA中我们匹配表达式<w:t>(\S+?)</w:t>就可以匹配到文本。表达式的写法和效果可能因具体平台而异。

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:79
阅读量:76
阅读量:43
阅读量:49
阅读量:83