Scrapy基础使用实例
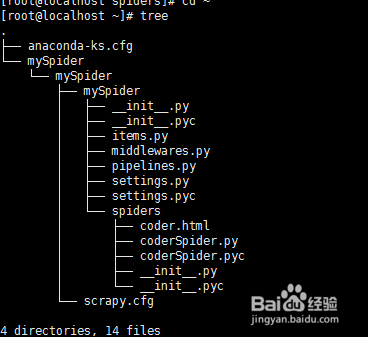
1、root用户使用XShell连上CentOS7机器,已经新建了scrapy工程,tree命令显示当前目录结构。tree
2、进入spider文件夹,新建文件coderSpider.pycd mySpider/mySpider/mySpider/spiders/vi coderSpider.py

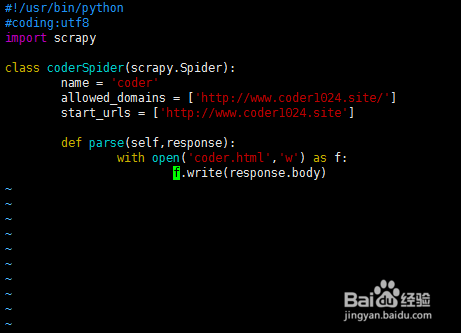
3、在coderSpider.py中编写代码如下:#!/usr/bin/python#罕铞泱殳coding:utf8足毂忍珩import scrapyclass coderSpider(scrapy.Spider): name = 'coder' #爬虫名 allowed_domains = ['http://www.coder1024.site/'] #允许的域名 start_urls = ['http://www.coder1024.site'] # 开始爬地址 def parse(self,response): with open('coder.html','w') as f: f.write(response.body)
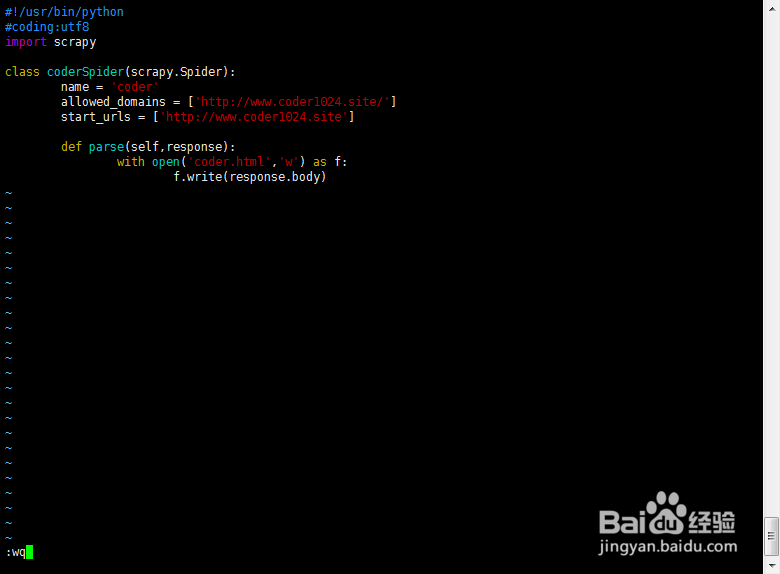
4、ESC退出编辑模式,保存退出:wq
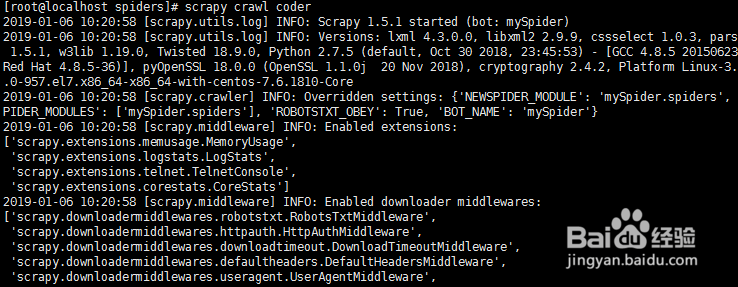
5、运行命令scrapy crawl coder
6、运行完成后,爬虫关闭,再spider文件夹,生成coder.html文件


声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:66
阅读量:90
阅读量:76
阅读量:58
阅读量:40