用Python(Jupyter Notebook)复刻A级论文
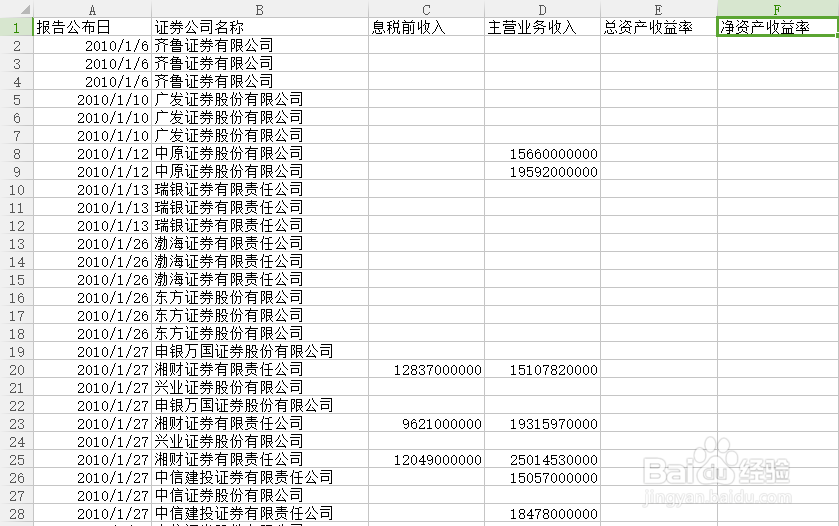
1、从数据库中下载各证券公司的相关数据,并进行筛选和处理。(注:数据库需登录才能使用)
2、下载《1995-2015中国经济政策不确定性指数(斯坦福大学和芝加哥大学联合发布)》

3、随意新建一个文件夹,在箭头所示地方输入cmd,弹出黑框,进入控制面板;然后输入 jupyter notebook,进入网页。

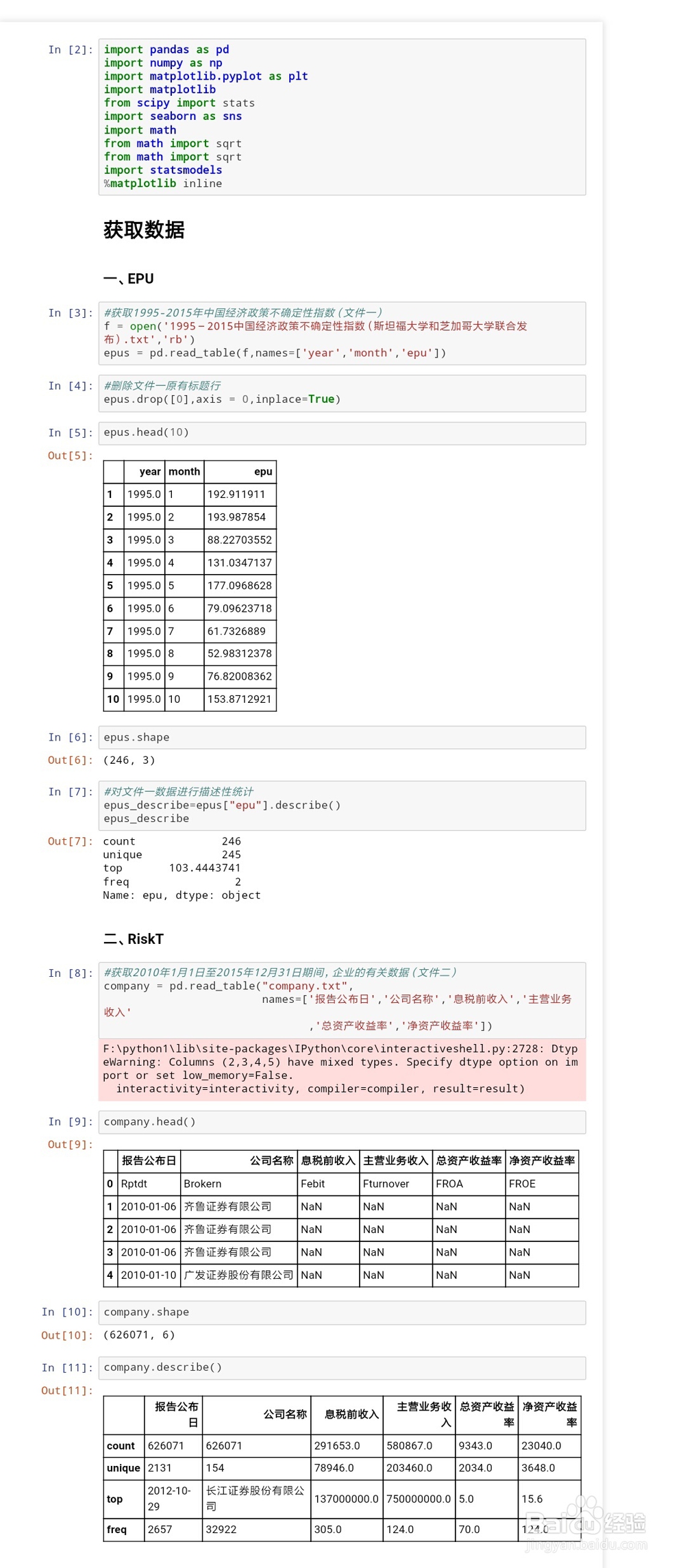
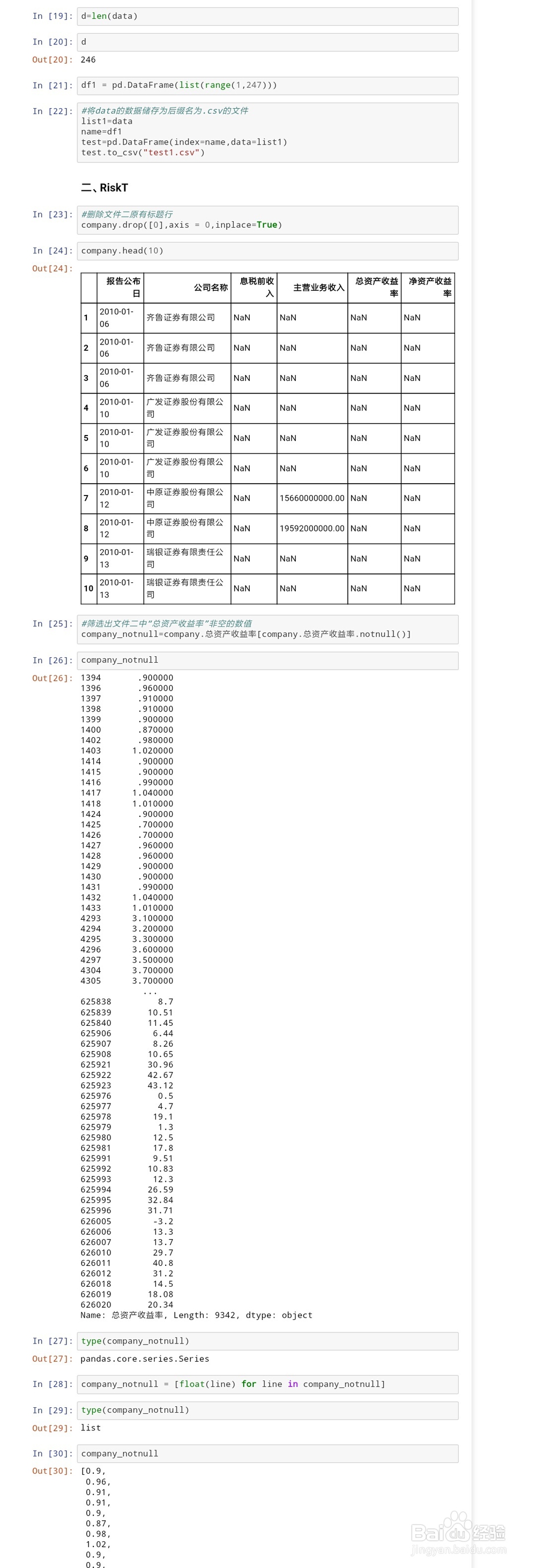
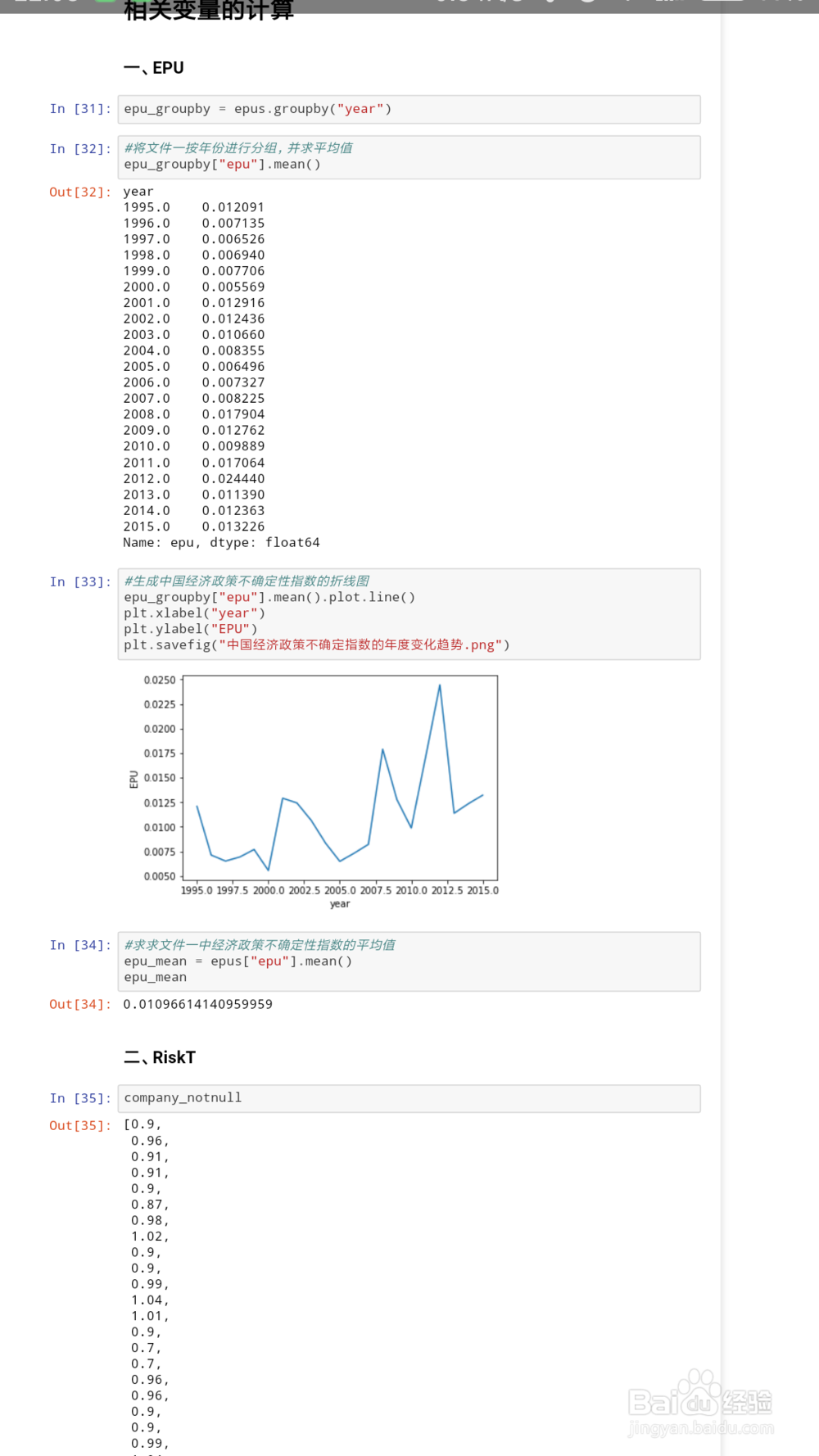
4、进行程序的编写,主代码如下(#之后内容为备注),详细内容见截图所示:import pandas as pdimport 荏鱿胫协numpy as npimport matplotlib.pyplot as pltimport matplotlibfrom scipy import statsimport seaborn as snsimport mathfrom math import sqrtfrom math import sqrtimport statsmodels%matplotlib inline#获取1995-2015年中国经济政策不确定性指数(文件一)f = open('1995-2015中国经济政策不确定性指数(斯坦福大学和芝加哥大学联合发布).txt','rb') epus = pd.read_table(f,names=['year','month','epu'])#删除文件一原有标题行epus.drop([0],axis = 0,inplace=True)#对文件一数据进行描述性统计epus_describe=epus["epu"].describe()epus_describe#获取2010年1月1日至2015年12月31日期间,企业的有关数据(文件二)company = pd.read_table("company.txt", names=['报告公布日','公司名称','息税前收入','主营业务收入' ,'总资产收益率','净资产收益率']) #使用float()函数将文件一中str类型转换浮点型epus["epu"] = [float(line) for line in epus["epu"]]#消除数量级差异,减少计算误差epus["epu"] = epus.epu/10000.0def epu(df): df["EPU"] = df.epu/10000.0 return df#将计算结果生成新的数列,并添加在原列表中epus.apply(epu,axis=1).head()epus["epu"].describe()#将新生成的数据集储存为.csv文件epus.apply(epu,axis=1).to_csv("epu_new.csv")#提取excel文件中的“EPU”列,并生成listimport xlrddata = xlrd.open_workbook('epu_new.xls')table = data.sheet_by_index(0)data = [table.cell(i,ord('E')-ord('A')).value for i in range(1, 247)]df1 = pd.DataFrame(list(range(1,247)))#将data的数据储存为后缀名为.csv的文件list1=dataname=df1test=pd.DataFrame(index=name,data=list1)test.to_csv("test1.csv")#筛选出文件二中“总资产收益率”非空的数值company_notnull=company.总资产收益率[company.总资产收益率.notnull()]company_notnull = [float(line) for line in company_notnull]epu_groupby = epus.groupby("year")#将文件一按年份进行分组,并求平均值epu_groupby["epu"].mean()#生成中国经济政策不确定性指数的折线图epu_groupby["epu"].mean().plot.line()plt.xlabel("year")plt.ylabel("EPU")plt.savefig("中国经济政策不确定指数的年度变化趋势.png")#求求文件一中经济政策不确定性指数的平均值epu_mean = epus["epu"].mean()epu_mean#计算文件二中企业风险承担水平=总资产收益率未来累计滚动标准差def handle(self): list_new=[] value=[] while len(self)!=0: list_new.append(self.pop()) while len(list_new)>=2: pro(list_new) value.append(pro(list_new)) break return valuedef pro(self): sum1=0 for i in self: #求和 sum1=int(i)+sum1 #算平均数 argv=int(sum1/len(self)) aa=0 for j in self: #计算方差 aa=aa+np.square(int(j)-argv) #开方得标准差 RiskT1=math.sqrt(aa/len(self)) return RiskT1company_notnull.reverse()RiskT=handle(company_notnull)df2 = pd.DataFrame(list(range(1,9342)))#将RiskT的数据储存为后缀名为.csv的文件list2=RiskTname=df2test=pd.DataFrame(index=name,data=list2)test.to_csv("test2.csv")#计算企业风险承担与经济政策不确定性的相关系数def multipl(a,b): sumofab=0.0 for i in range(len(a)-9095): temp=a[i]*b[i] sumofab+=temp return sumofabdef corrcoef(x,y): n=len(x) #求和 sum1=sum(x) sum2=sum(y) #求乘积之和 sumofxy=multipl(x,y) #求平方和 sumofx2 = sum([pow(i,2) for i in x]) sumofy2 = sum([pow(j,2) for j in y]) num=sumofxy-(float(sum1)*float(sum2)/n) #计算皮尔逊相关系数 den=sqrt((sumofx2-float(sum1**2)/n)*(sumofy2-float(sum2**2)/n)) return num/denx = RiskTy = dataprint (corrcoef(x,y))#读取新生成的有关企业风险承担与经济政策不确定性指数的csv表格huigui = pd.read_csv("test.csv",names=['epu','RiskT']) from sklearn import linear_model#建立线性回归模型regr = linear_model.LinearRegression()#拟合regr.fit(huigui['epu'].reshape(-1, 1), huigui['RiskT'])#得到直线的斜率——a,截距——ba, b = regr.coef_, regr.intercept_print("a=",a)print("b=",b)import seaborn as sns # 使用散点图可视化x和y之间的关系,并添加一条最佳拟合直线和95%的置信带sns.pairplot(huigui, x_vars='epu', y_vars='RiskT', size=5, aspect=2.0, kind='reg')plt.show()#将拟合的直线单独提出,更明显、直观plt.plot(huigui['epu'], regr.predict(huigui['epu'].reshape(-1,1)), color='red', linewidth=4)plt.show()


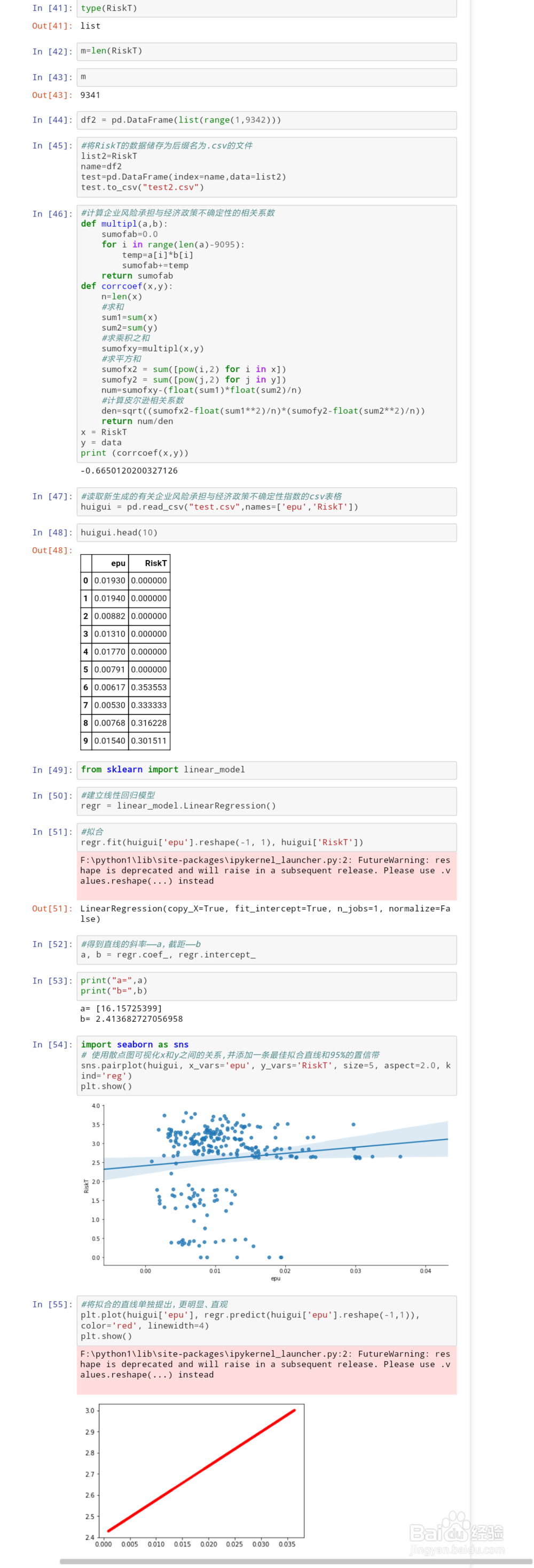
5、得出结论:1.受数据的可用性、有效性的影响,本文只验证了假设H1a与假设H1b,洵翌绦枞证实其结果均与原论文相符合;2.本文对经济政策不确定佣甲昭宠性如何影响企业风险承担进行了实证检验,经过以上数据的分析和计算,本文验证了经济政策不确定性提升了中国企业的风险承担水平。上述结果意味着,在中国制度背景下,经济政策不确定性的“机遇预期效应”在上市公司中发挥主导作用;3.唯一与原论文结果差异较大的就是回归系数,虽然其对最终的结论并未造成大的影响,但对于直线的拟合、数据分布规律的分析均带来了一定的误差,分析其可能的原因,我认为应该是滚动标准差RiskT的计算结果与原论文差距较大——为了便于计算,我将未来五年滚动标准差改为了未来累计滚动标准差——使得数据分布的波动更大,便于计算的同时却也带来了较大的误差,影响了回归系数的计算。4.经济政策不确定性引发企业风险承担水平的提高,表明政府在执行宏观调控职能时也要关注政策调整对企业经营产生的潜在影响。当政府决定改变现行经济政策时,要尽可能保持新政策的长期性和稳定性;5.对企业而言经济政策不确定既可能蕴含投资机遇,也可能增大投资风险。在经济政策不确定环境下,企业要保持清醒的头脑,合理研判未来的政策走势。此外,企业需要完善内部激励和决策机制,合理利用经济政策不确定下的有利机会,在激烈的市场竞争中脱颖而出。