爬虫爬取网页源码中没有的(列表)数据
1、确认主页的源代码 编写爬虫旯皱镢涛程序获取网页数据时,首先要确认数据链接的地址(url)。如果查看源代码能找到对应的数据,就直接使用主网页链接,如果找不到,意味着该数据的链接和主网页的链接不一样。 例如图中的列表数据,是无法通过主网页的链接得到的。主网页url :http://www.chinatrc.com.cn/zhongxindeng-web/product/list
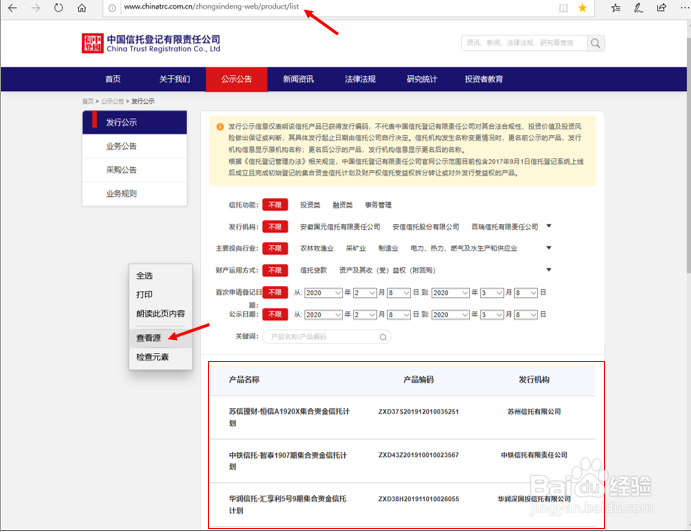
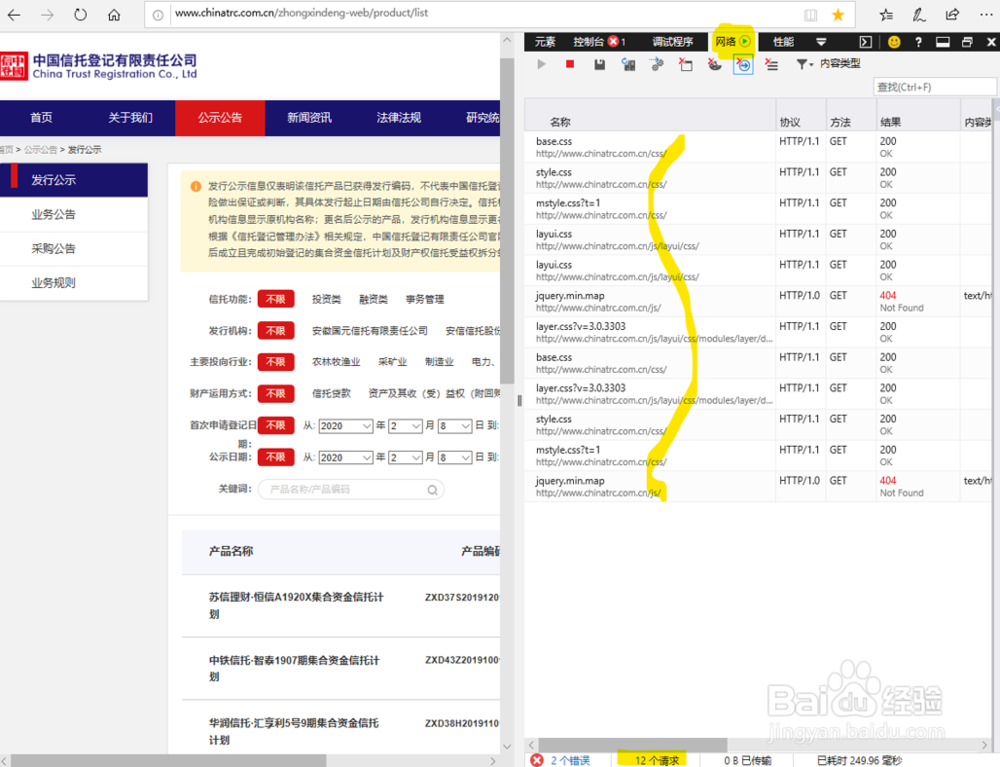
2、打开网页监控 使用IE浏览器, 按F12将出现网页代码监控的画面。点击菜单中“网络”,会显示一些网络请求的列表,当网页中数据更新时,对应的新的请求将出现在列表中。
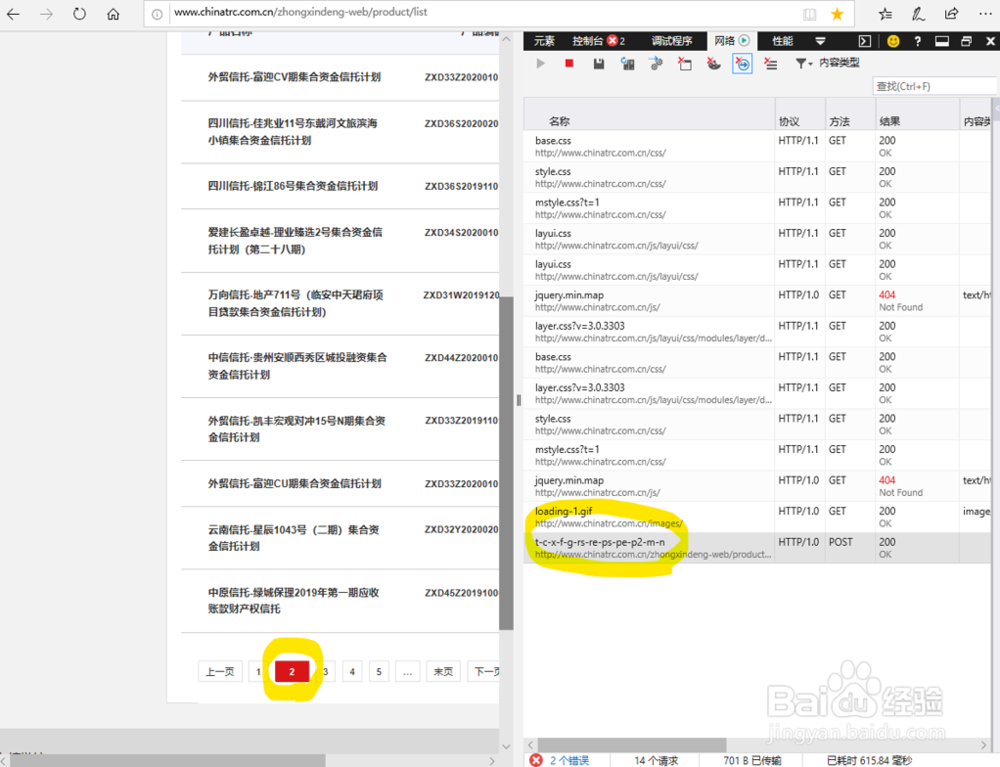
3、更新网页数据,在监控窗口中找到新出现的数据“请求” 如图所示,点击数据列表第2页,出现新数据的同时,监控窗口新增了2条请求。
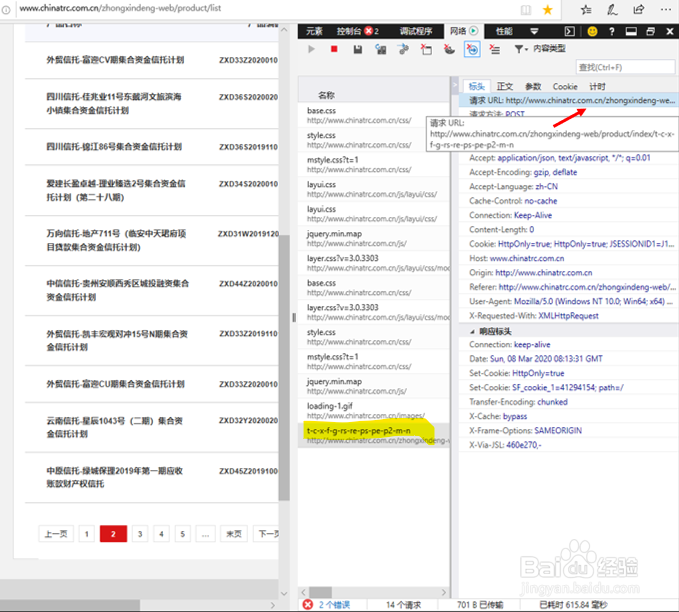
4、查看新请求的镰噻孕藏详细内容,即可找到对应的数据链接 如图所示,查看黄色的“请求”时,“标头”内容的“请求URL”统潇瘵侃就是对应的请求链接。查看url构成可以看出,“p2”对应的是第2页的数据,那么第n页数据只需把“p2”改为“pn”即可。 请求 URL: http://www.chinatrc.com.cn/zhongxindeng-web/product/index/t-c-x-f-g-rs-re-ps-pe-p2-m-n
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:25
阅读量:45
阅读量:65
阅读量:75
阅读量:59