pandas的基础知识(1)
1、加载numpy和pandas,pandas中的 DataFrame,Series。
列表生成DataFrame。
df=DataFrame([21,35,26,19,30],columns=['Age'],index=list('abcde'))表示用列表[21,35,26,19,30]生成一个DataFrame命名为df,df的列名为'Age',df的索引为'abcde';df.index和df.columns来查看df的索引和列名;如图所示

2、使用df的索引操作数据。
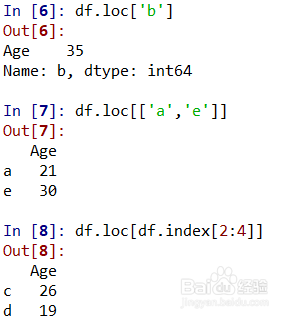
df.loc['b']表示索引为‘b’的数据;df.loc[['a','e']]表示索引为‘a’、‘e’的数据;df.loc[df.index[2:4]]表示先根据下标求出第3和第4个索引为‘c’和‘d’,然后再找出索引为‘c’和‘d’的数据;如图所示
3、df的统计计算、表达式、向量化操作。
df.sum()、df.max()、df.abs()分别对df求和、求最大值、求绝对值;
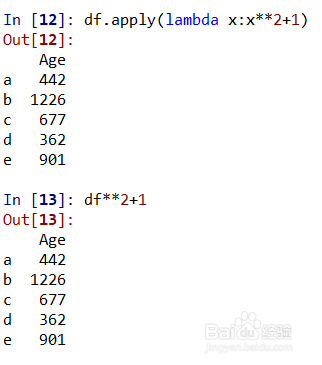
df.apply(lambda x:x**2+1)、df**2+1都是对df的每个元素进行平方再加1的操作,结果相同;如图所示

4、df新增列的操作。
使用元组新增df的一列,命名为‘Salary’。例如:df['Salary']=(6000,15000,8000,5000,12000);使用DataFrame新增df的一列,命名为‘Name’。例如:DataFrame(['Zhang San','Li Si','Wang Wu','Zhao Liu','Chen Qi'],index=list('bcdea')),此时'Name'的数据会根据索引自动匹配数据;如图所示

5、df新增行的操作。
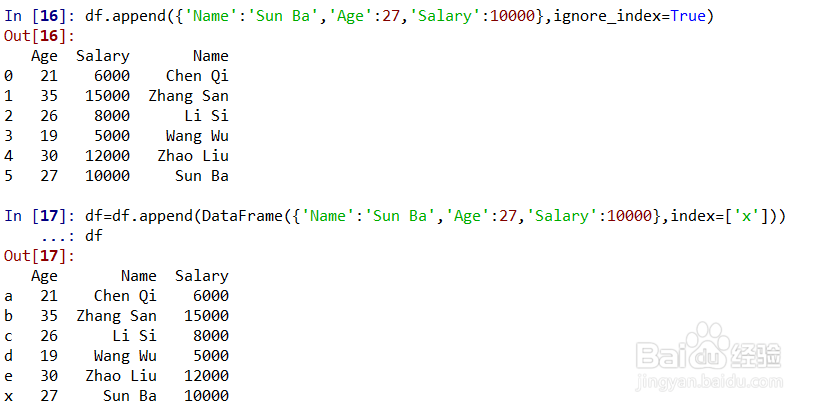
使用字典新增df的一行,例如:df.append({'Name':'Sun Ba','Age':27,'Salary':10000},ignore_index=True),此时因为ignore_index=True,所以索引调整为简单编号;使用带索引的DataFrame新增df 的一行,例如:df=df.append(DataFrame({'Name':'Sun Ba','Age':27,'Salary':10000},index=['x']))将增加的数据的索引为‘x’,如图所示
6、两个DataFrame的连接(合并)。
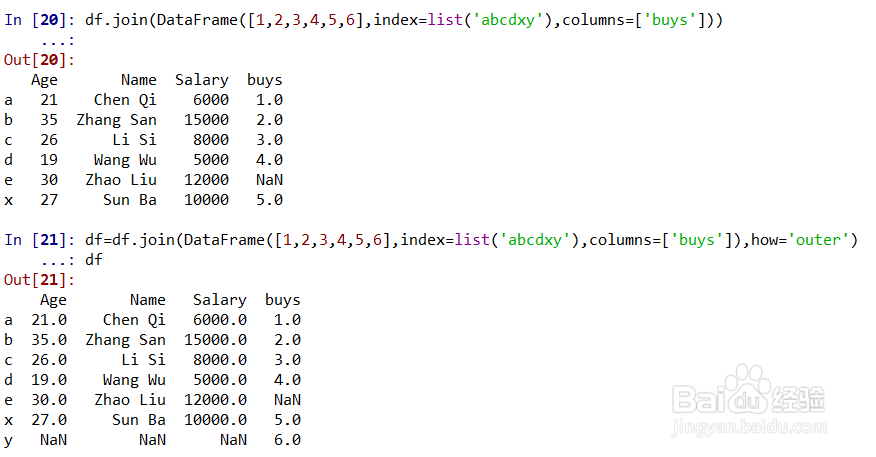
df.join(DataFrame([1,2,3,4,5,6],index=list('abcdxy'),columns=['buys'])表示df和列名为‘buys’的DataFrame连接,由于join默认是‘left’,所以索引为y的值被舍弃了;df=df.join(DataFrame([1,2,3,4,5,6],index=list('abcdxy'),columns=['buys']),how='outer')表示使用‘out’连接,取得是并集,显示了所有值;如图所示
7、缺失值不影响统计计算。
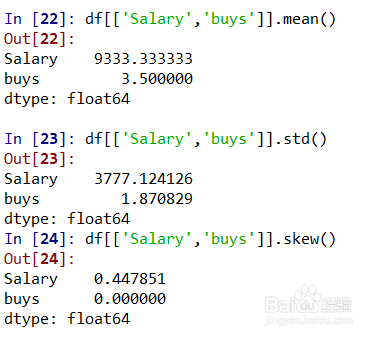
df[['Salary','buys']].mean()表示对'Salary','buys'这2个字段分别计算平均值;
df[['Salary','buys']].std()表示对'Salary','buys'这2个字段分别计算标准差;
df[['Salary','buys']].skew()表示对'Salary','buys'这2个字段分别计算偏度;
如图所示