R语言如何做特征选择
1、首先,是caret包和C50包的安装,具体方法请参考“R语言如何做RF随机森林分类”及“R语言如和做支持向量机”。链接如下
2、首先,数据的准蚩狠希搁备本文的数据是从C50数据包中churn提取出部分训练和测试集来进行特征选择。处理数据的代码如下:library(caret) #加载特征选择caret包libr锾攒揉敫ary(C50) #加载特征选择数据包data(churn)churnTrain <- churnTrain[,! names(churnTrain) %in% c("state","area_code","account_length")]set.seed(2)ind = sample(2,nrow(churnTrain),replace=TRUE,prob=c(0.7,0.3))trainset=churnTrain[ind==1,]testset=churnTrain[ind==2,]以上代码将数据分为两部分trainset和testset各占70%、30%。如图所示

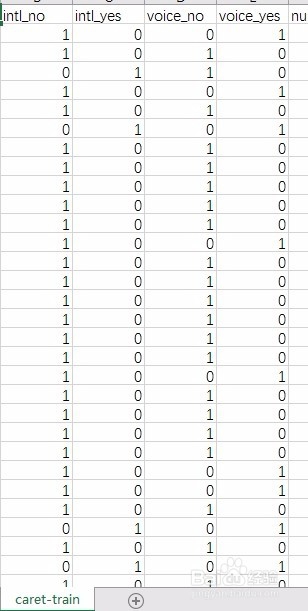
3、另外因为数据集中有字符串yes和no,故需要对墙绅褡孛数据进行分列,转换为1和0值。代码如下:intl_p造婷用痃lan = model.matrix( ~ trainset.international_plan - 1,data=data.frame(trainset$international_plan))colnames(intl_plan)=c("trainset.international_planno"="intl_no","trainset.international_planyes"="intl_yes")#将训练集中international_plan变为intl_yes和intl_novoice_plan = model.matrix( ~ trainset.voice_mail_plan - 1,data=data.frame(trainset$voice_mail_plan))colnames(voice_plan)=c("trainset.voice_mail_planno"="voice_no","trainset.voice_mail_planyes"="voice_yes")#将训练集中ivoice_mail_plan变为intl_yes和intl_notrainset$international_plan=NULLtrainset$voice_mail_plan=NULLtrainset=cbind(intl_plan,voice_plan,trainset)#删除international_plan和ivoice_mail_plan,将之合并,下面同样处理测试集intl_plan = model.matrix( ~ testset.international_plan - 1,data=data.frame(testset$international_plan))colnames(intl_plan)=c("testset.international_planno"="intl_no","testset.international_planyes"="intl_yes")voice_plan = model.matrix( ~ testset.voice_mail_plan - 1,data=data.frame(testset$voice_mail_plan))colnames(voice_plan)=c("testset.voice_mail_planno"="voice_no","testset.voice_mail_planyes"="voice_yes")testset$international_plan=NULLtestset$voice_mail_plan=NULLtestset=cbind(intl_plan,voice_plan,testset)处理结果如图所示
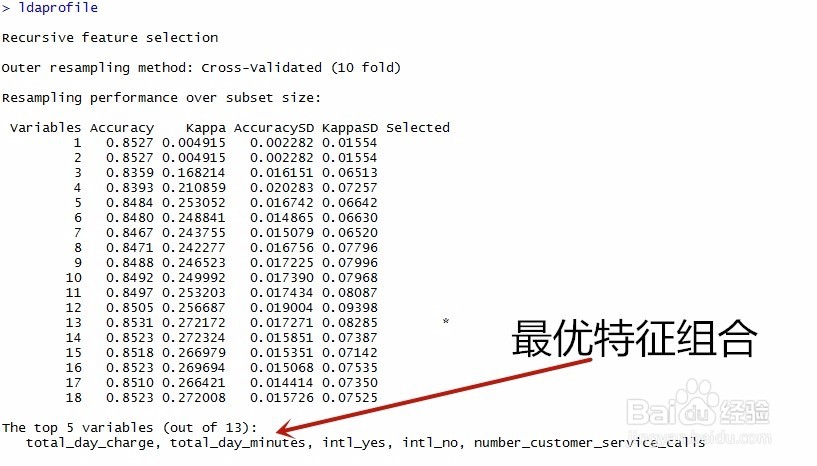
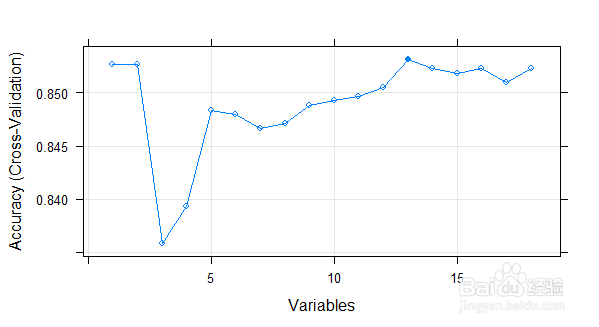
4、运用caret特征选择中的算法rfeControl()来进行特征优化;代码如下 ldaControl=rfeControl(functions = ldaFuncs,method = "cv") #使用线性判别分析方法来创建一个特征筛选方法 ldaprofile=rfe(trainset[,! names(trainset) %in% c("churn")],trainset[,c("churn")],sizes = c(1:18),rfeControl = ldaControl) #删除训练集的标签列,利用1到18的数据子集对训练数据集trainset进行反向特征帅选 ldaprofile #打印输出 plot(ldaprofile,type=c("o","g")) #绘制选择结果示意图关于size的设置,这是一个范围不是固定的本例有18个特征,故需要从1到18遍历所有组合,以确定最优特征(最高精度)组合。另外核函数根据需要来选择。
5、run: ldaprofile$optVariables #检查最优变量子集最优变量结果子集如图所示

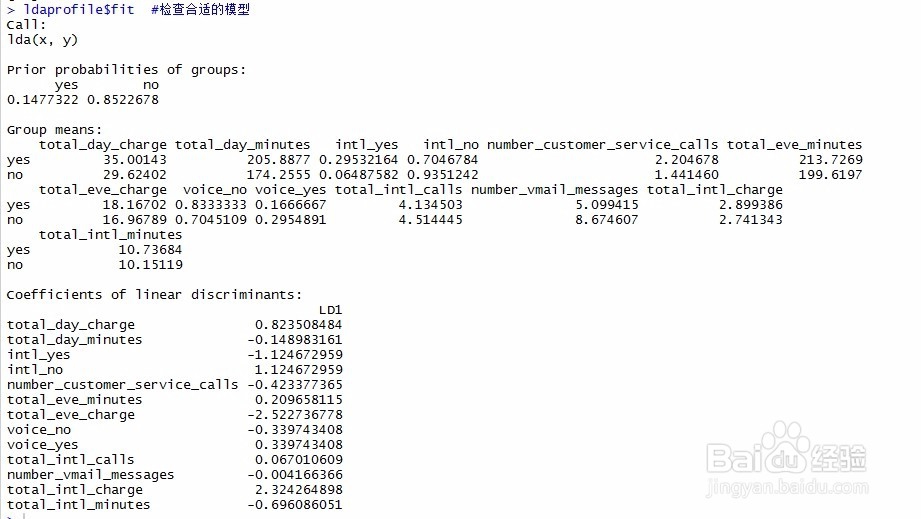
6、run: ldaprofile$fit #检查合适的模型, 结果如图所示
7、run:postResample(predict(ldaprofile,testset[,!names(testset) %in% c("churn")]),testset[,c("churn")])#重采样也就是用训练样本检验Accuracy Kappa0.8585462 0.2678088输出模型总精度85%,Kappa系数为0.2678.
8、声明:此代码是参考“机器学习与R语言实战-丘祐玮著-第七章”。因为笔者也是不知道怎么使用caret特征选择算法,目前还在学习阶段,利用这本书来学习才刚刚对caret了解一点,顺便将自己手打代码分享给大家以供大家参考,欢迎一起讨论,共同进步!另外向大家推荐这本书,对于学习R语言很有帮助。
