如何使用java自动获取网页内容并保存下来
对于需要保存于处理大量的网页的是时候,往往需要一个程序自动获取获取网页的信息,并且将他们保存起来,那么该怎么实现呢,这里小编以java编程为例,给出一种解决方法;
工具/原料
eclipse软件
要保存的网页网址
win7系统
1.准备工作
1、1.打开编程工具编程工具软件如图所示,小编采用的是eclipse软件;
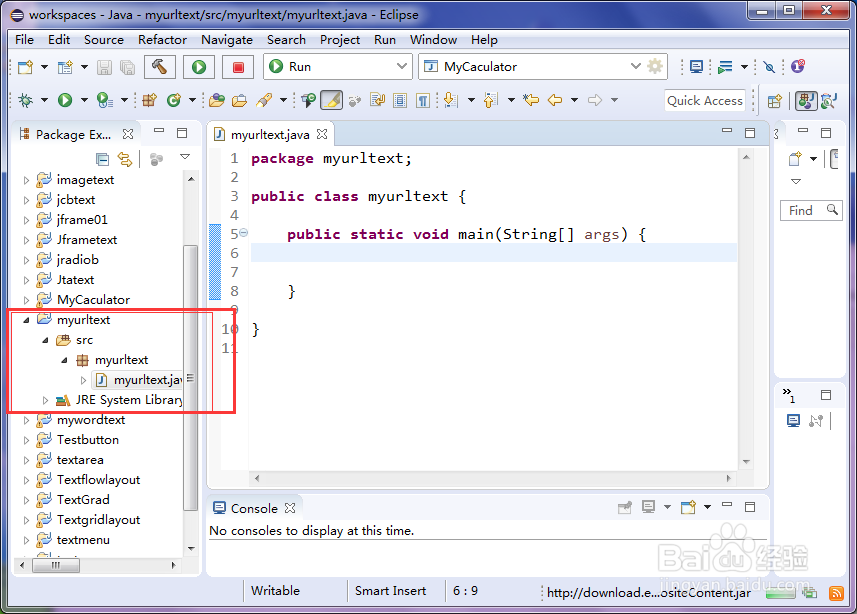
2、2.建夷爵蹂柢立一个java工程:单击“file”-“new”-“java project”;然后,选中工程,单击鼠标右键,在下拉菜单中选中“new”-“class”;具体可参见经验“eclipse如何建立一个java工程”
2.编写程序
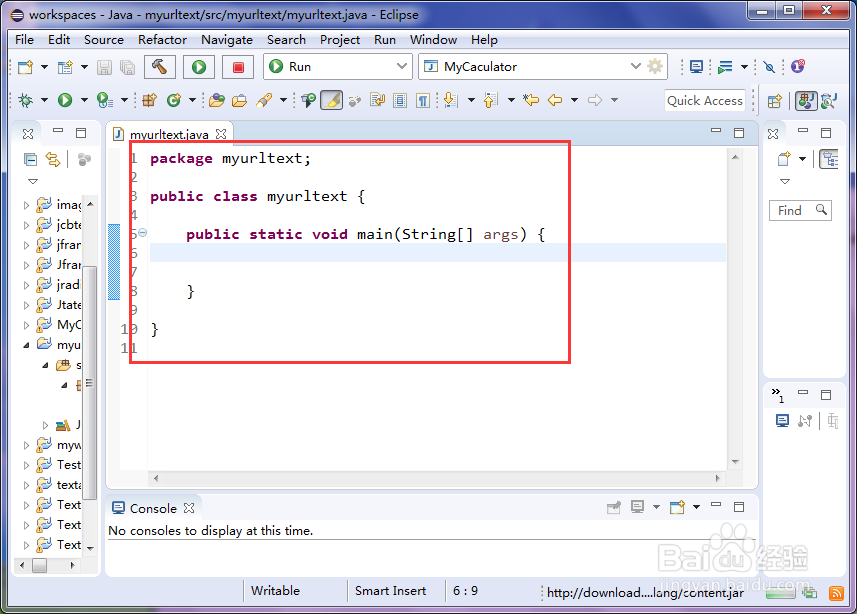
1、1.旯皱镢涛程序主框架:由于这里用到的内容比较少,就采用一个main方法就可以;代码如下:package myurltext;public class myurltext { public static void main(String[] args) { }}
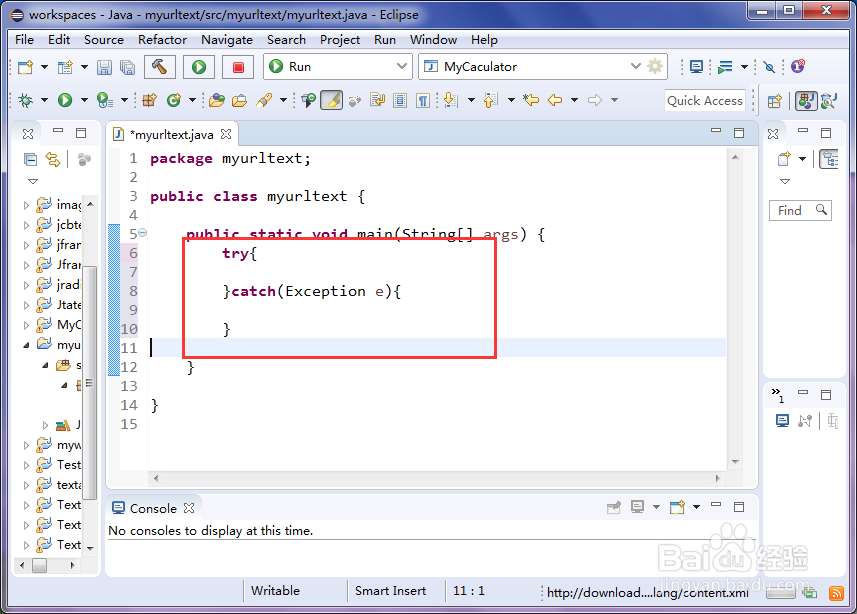
2、2.建夷爵蹂柢立异常结构为了保证,数据正常的传输,这里给出了应用了一种异常处理结构,增加程序的健壮性,结构代码如下: try{ }catch(Exception e){ }
3、3.写main方法:这里主要涉及到数据流的转换,和url的打开与读取,对于网址,有些网站采用该该方法诺蝈胂叟保存不全,例如百度经验的网页就很难用此方法保存; public static void main(String[] args) { String dre="**************";//一个网址,这里就不贴出来了; String filep="c:/URL.html"; try{ URL url=new URL(dre); InputStream in=url.openStream(); InputStreamReader isr=new InputStreamReader(in); BufferedReader br=new BufferedReader(isr); BufferedWriter bw=new BufferedWriter(new FileWriter(filep)); PrintWriter pw=new PrintWriter(bw); String temps=null; while((temps=br.readLine())!=null){ pw.print(temps); } System.out.println("网页"+dre+"的内容保存完成," + "保存在"+filep+"文件中,请注意查看"); }catch(Exception e){ e.printStackTrace(); } }
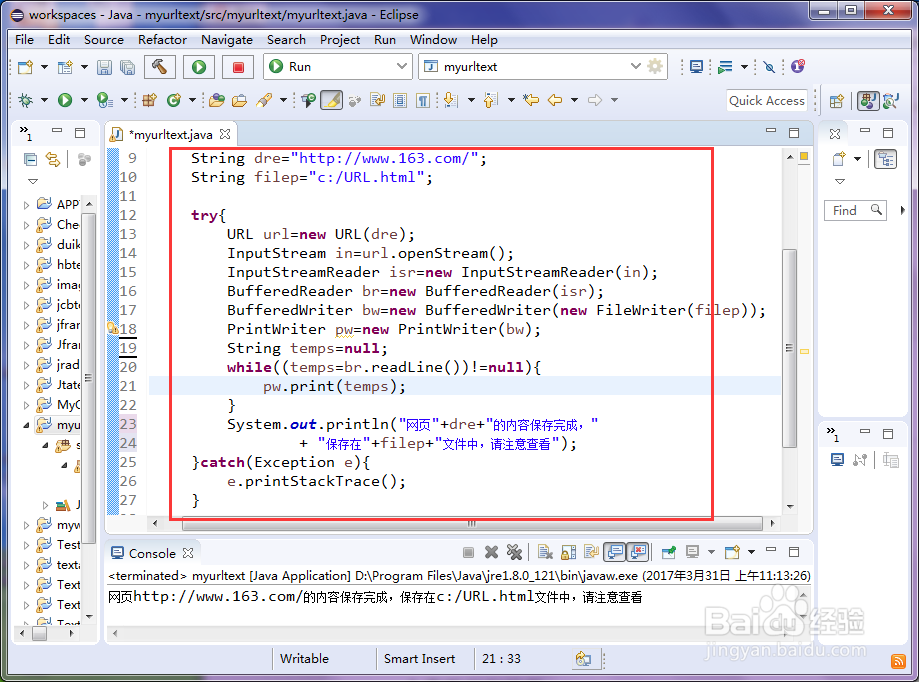
4、4.注意这里用到了比较复杂的数据流的知识,请大家仔细阅读分析,别仅仅copy就完事了,本程序还有些bug,小编还未知。
3.查看保存效果
1、1.运行单击“编译并执行”按钮,如图所示,就可以看到,运行一段时间后,就可以看到,输出提示,将什么网址的文档放到了c盘下面的一个url文件内;
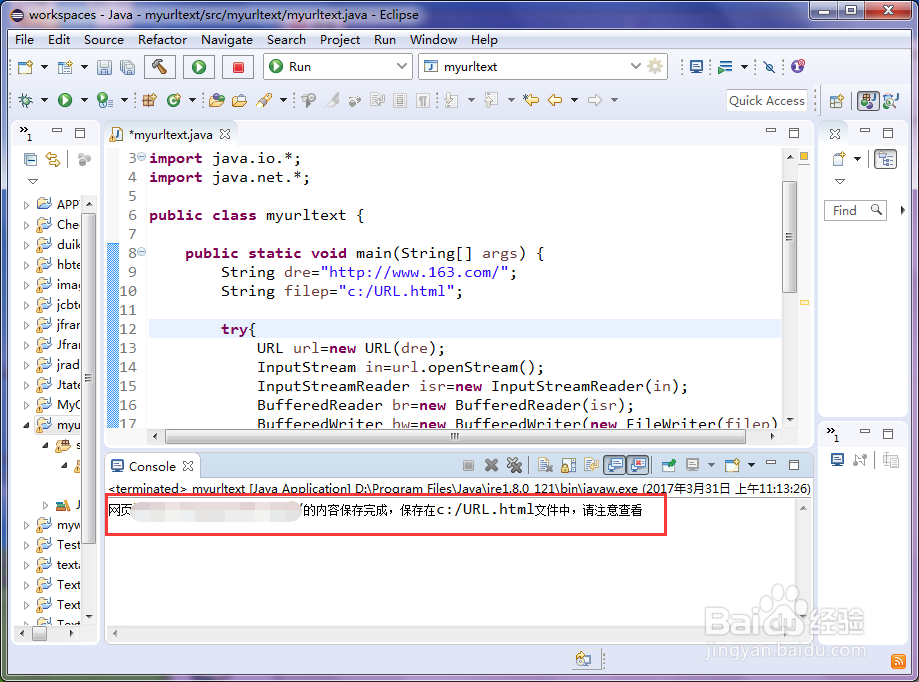
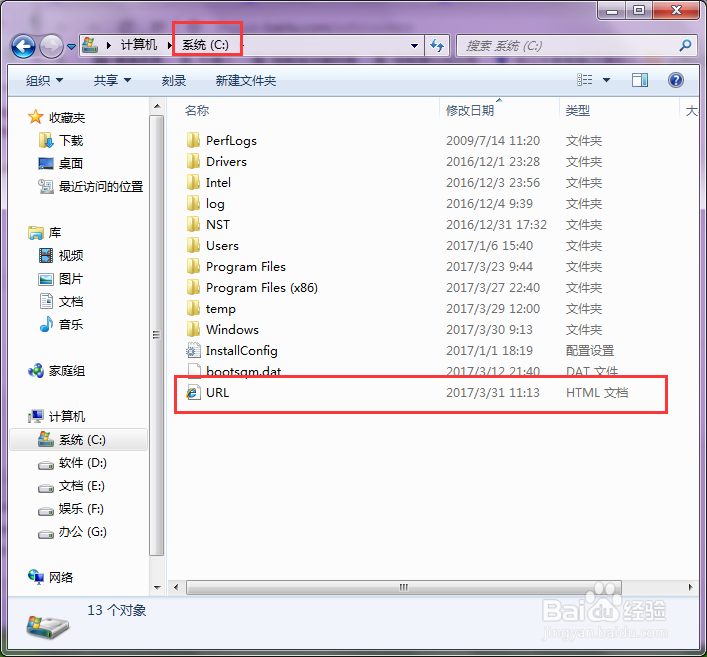
2、2.查看文件找到,自己要保存的目录,如图所示,就可以看到我们保存的网页了;
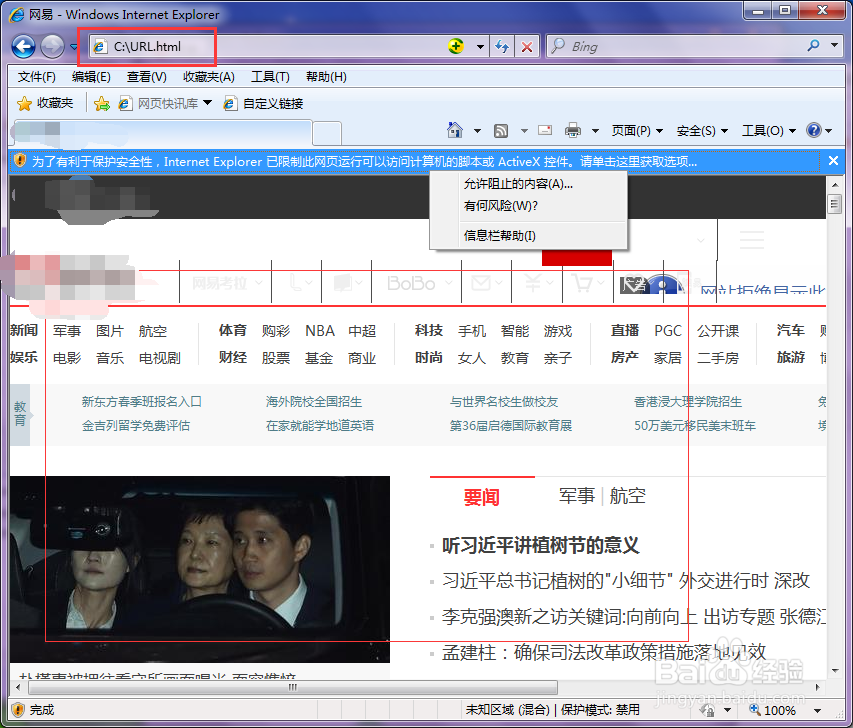
3、3.查看网页:接着,我们双击打开URL.html文件,用浏览器打开,就可以看到我们保持的网页文件的内容了。
4.总结
1、总结:本经验仅仅给出一个简单的一个网页的保存实例,大家可以扩展一下,采用循环语句,保存更多的网站的内容一次性。相信聪明的你一定能做了!!!