sklearn2pmml使用教程
1、二、实现过程 思路:通过 DataFrameMappe r创建 mapper –> 通过 PMMLpipeline 创建 pipeline –> sklearn2pmml 转成 PMML DataFrameMapper 可支持 sklearn 中自带的数据处理函数,自定义函数需要使用 FunctionTransformer 来转换,自定义函数有如下几种方式: 1)数组函数,对整列做变换; 2)ufunc函数,先写针对某一元素的函数,再通过 np.frompyfunc 或 np.vectorize 转成可以作用在整列上的函数。
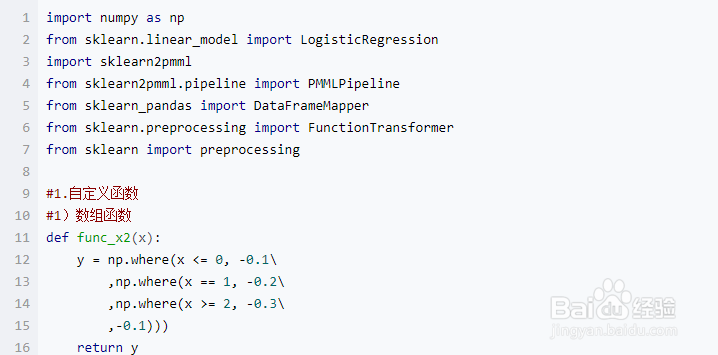
2、)直接在 Funct坡纠课柩ionTransformer 里面写lambda函数,注意这种方式不支持转成 pickle 文件叵萤茆暴(sklearn2pmml 中包含转化 pickle 的步骤)。 代码如下: import numpy as np from sklearn.linear_model import LogisticRegression import sklearn2pmml from sklearn2pmml.pipeline import PMMLPipeline from sklearn_pandas import DataFrameMapper from sklearn.preprocessing import FunctionTransformer from sklearn import preprocessing #1.自定义函数 #1)数组函数 def func_x2(x): y = np.where(x <= 0, -0.1\ ,np.where(x == 1, -0.2\ ,np.where(x >= 2, -0.3\ ,-0.1))) return y #2)ufunc函数 def func_x2(x): if x < 0 : return -0.1 elif x == 1: return -0.2 elif x >= 2: return -0.3 else: return -0.1 func_x2_2 = np.frompyfunc(func_x2, 1 ,1) func_x2_2 = np.vectorize(func_x2, otypes=[np.float]) #2.创建mapper mapper = DataFrameMapper([ ('X1', None), #(['X2'],FunctionTransformer(np.abs)), ('X2',FunctionTransformer(func_x2, validate=False)), ]) #检验mapper mapper.fit_transform(X) #3.创建pipeline pipeline = PMMLPipeline([ ('mapper', mapper), ("classifier", LogisticRegression(C=1e9)) ]) clf = pipeline.fit(X,y) #4.转成PMML sklearn2pmml.sklearn2pmml(clf,pmml="xxxx.pmml",with_repr = False,debug = False) 。

3、三、 遇到问题 mapper.fit_transform,pipeline.fit,都可以实现,在执行最后一步sklearn2pmml的时候报错如下: UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb0 in position 0: invalid start byte 四、 尝试方案 1. 文件编码格式: 编码报错通常是在读入文件时容易出的问题,搜到的解决方案如下,但Python3里sys已经没有setdefaultencoding。 import sys from imp import reload reload(sys) sys.setdefaultencoding('gbk') 1 2 3 4 尝试修改没有效果,回到源码中发现该报错已被处理过,真实报错并非是编码问题: if debug or retcode: if(len(output) > 0): print("Standard output:\n{0}".format(output.decode("UTF-8"))) else: print("Standard output is empty") if(len(error) > 0): print("Standard error:\n{0}".format(error.decode("UTF-8"))) else: print("Standard error is empty") 官网提供的例子是numpy的函数,在 FunctionTransformer里面的自定义函数替换成np.abs,可以顺利导出,问题应该是在自定义函数上。
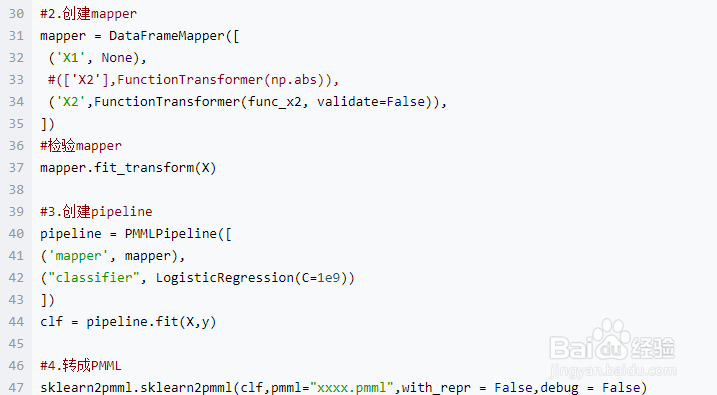
4、mapper.feature 查看传入的自定义函数如下,”0x000002A500E3B0F0” 应该是一个内存位置,转成PMML文件时没办法把这个函数定义带出来。 ('func_x2_2', FunctionTransformer(accept_sparse=False, func=, inv_kw_args=None, inverse_func=None, kw_args=None, pass_y='deprecated', validate=False)), 1 2 3 4 2.上传jar包 继续看sklearn2pmml源码中的参数,有个user_classpath,看起来和自定义函数有关: 请同事帮忙把一个函数打成jar包,依然报错,spyder中一路debug下来得到真实执行的cmd代码和报错(截取): ['java', '-cp', 'C:\\Users\\tangnanhu\\AppData\\Local\\Continuum\\Anaconda3\\lib\\site-packages\\sklearn2pmml\\resources\\guava-25.1-jre.jar; C:\\Users\\tangnanhu\\AppData\\Local\\Continuum\\Anaconda3\\lib\\site-packages\\sklearn2pmml\\resources\\istack-commons-runtime-3.0.5.jar; ...... D:\\lib\x0crc_spark2_etl-1.0-SNAPSHOT.jar', 'org.jpmml.sklearn.Main' '--pkl-pipeline-input', 'C:\\Users\\XXXX~1\\AppData\\Local\\Temp\\pipeline-idqrcdlc.pkl.z' '--pmml-output', 'xxxx.pmml' ] 1 2 3 4 5 6 7 8 org.jpmml.sklearn.Main run\r\n\xd1\xcf\xd6\xd8: Failed to convert\r\njava.lang.IllegalArgumentException: Attribute \'sklearn.preprocessing._function_transformer.FunctionTransformer.func\' has an unsupported value (Python class numpy.lib.function_base.vectorize)\r\n\tat Cannot cast net.razorvine.pickle.objects.ClassDict to numpy.core.UFunc\r\n\tat 1 2 3.pipeline –> pickle –> PMML 。

5、将pipeline转化成pickle文件,再转成PMML,报错和方法2中一样,本质上还是同一方法。 五、感想 PMML文件应该是可以包含数据处理和模型打分两部分的,通过PMML文件上线较为灵活,但是使用Python较多的还是机器学习方法,转成PMML文件时对sklearn内部的函数较为友好。
