如何使用python爬取电影资源(经典实战版)
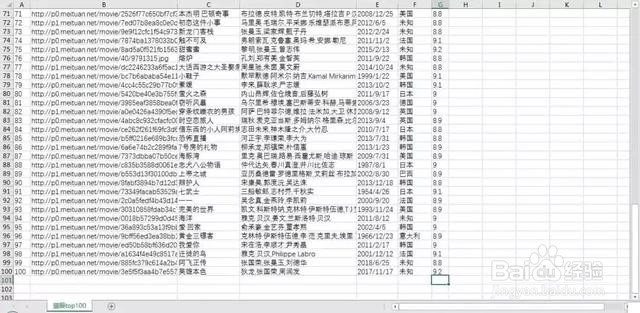
1、首先说一下我们的终极目标:从网页中提取出top100电影的电影名称、封面图片、排名、评分、演员、上映国家/哪纳紧萄地区、评分等信息,并保存为csv文本文件。根据爬取结果,进行简单的可视化分析,最终完成类似下图所示
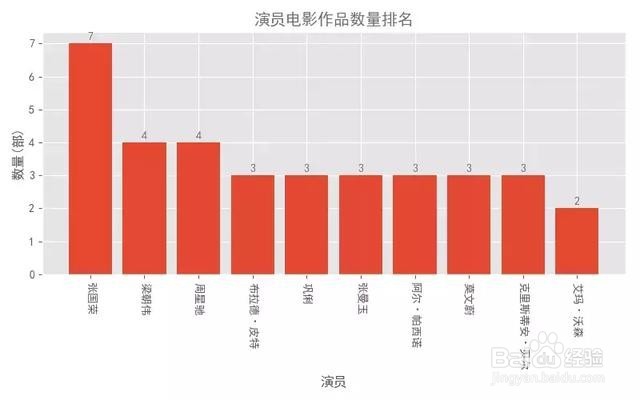
2、数据分析类似下图所示
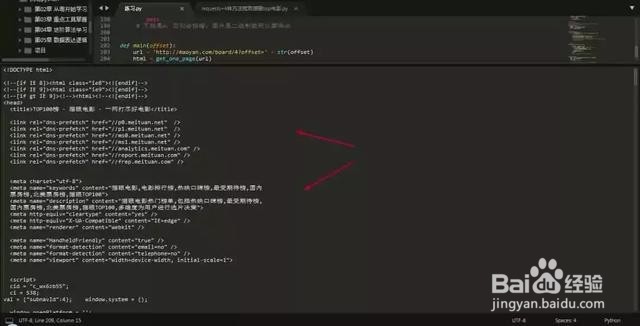
3、好了,现在就开始一步一步来教士候眨塄大家,第一步我们要分析目标网址规则,首先,打开猫眼Top100的url网址: http://maoyan.com/board/4?offset=0。页面非常简单,所包含的信息就是上述所说的爬虫目标。下拉页面到底部,点击第2页可以看到网址变为:http://maoyan.com/board/4?offset=10。因此,可以推断出url的变化规律:offset表示偏移,10代表一个页面的电影偏移数量,即:第一页电影是从0-10,第二页电影是从11-20。因此,获取全部100部电影,只需要构造出10个url,然后依次获取网页内容,再用不同的方法提取出所需内容就可以了。
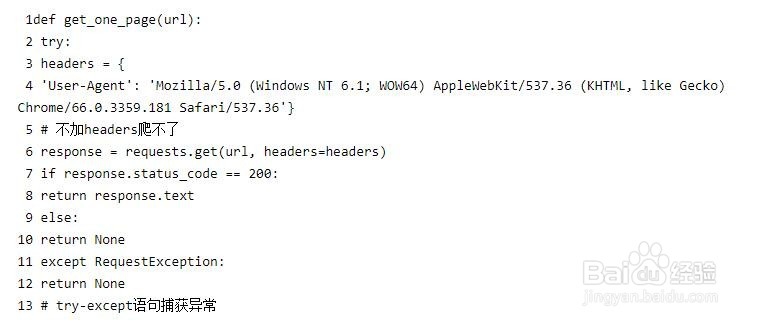
4、下面使用Requests畛粳棠奈获取首页数据,先定义一个获取单个页面的函数:get_one_page(),传入url参数。如下图所示
5、接下来在main()函数中设置url,如下图所示

6、开始提取关键内容。右键网页-检查-Network选项,选中左边第一个文件然后定位到电影信息的相应位置,如下图:
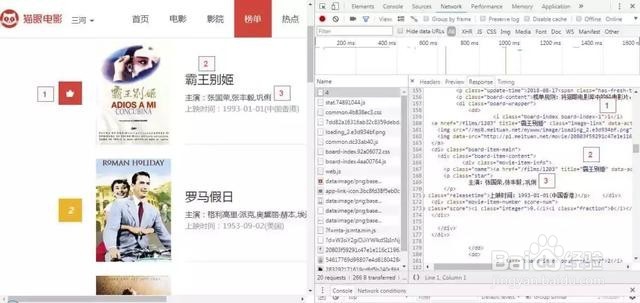
7、用正则写下主演、上映时间和评分等内容,完整的正则表达式如下图所示

8、接下来,修改main()函数来输出爬取的内容,如下图所示

9、运行程序,就可成功地提取出所需内容,结果如下:

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:62
阅读量:39
阅读量:45
阅读量:87
阅读量:35