使用selenium和requests,下载mmjpg上所有的图片
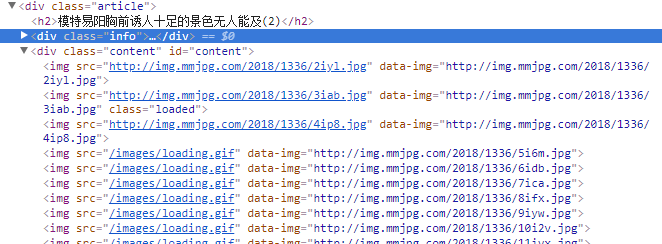
1、首先,分析网页,网站的URL都很有规律,没个美女的套图是这样http://www.mmjpg.com/mm/1336 ,从1到1336,每张大图的地址是在id为"content"的div标签里面,如图:
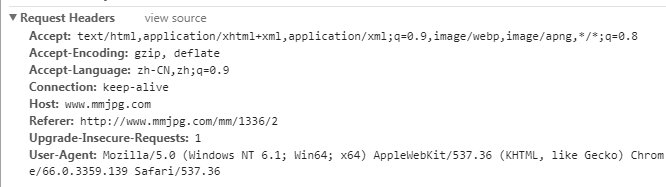
2、然后爬取的思路就很清晰了,从1到1336,依次获取并打开每一份套图的地址,接着点击所有图片的元素链接,加载出所有图片的地址,再根据获得的图片地址写入到本地文件中。这里有个需要注意的地方,当程序不加任何headers直接打开图片地址时,会跳转到同一页面,所以放弃了urllib.request.urlretrieve来下载图片,因为我还没找到怎么在里面加head头信息的方法,跳转的地址如下图:

3、这时只要加上head头信息就可以解决了,其中关键值是referer,只要是本地域名下都可以,告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。
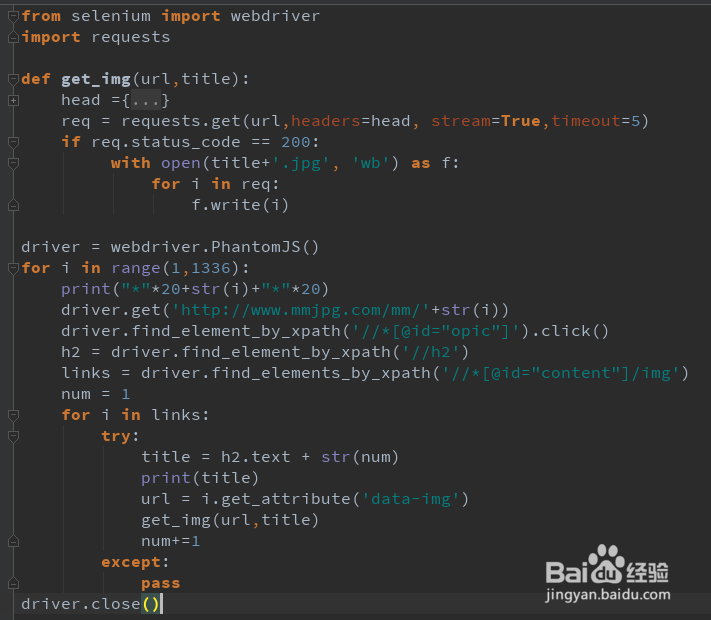
4、代码如下:用了比较简单的代码。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:94
阅读量:90
阅读量:26
阅读量:65
阅读量:22