扫描的图片(PDF文件)中的文字如何快速提取
1、在百度里搜索“汉王ocr文字识别软件”,好多网站都可以下载,文件不大,只有30M左右。安装版、绿色版都可以。

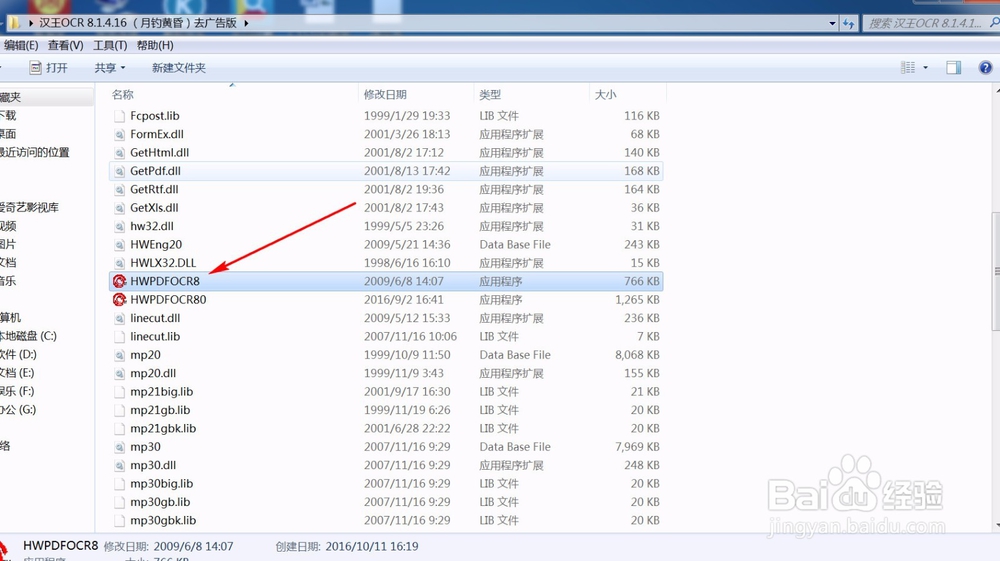
2、下载好文件,解压出来后,运行软件程序,如图。第一次运行可能会需要更新程序,直接更新就好了。打开后的界面见下图。
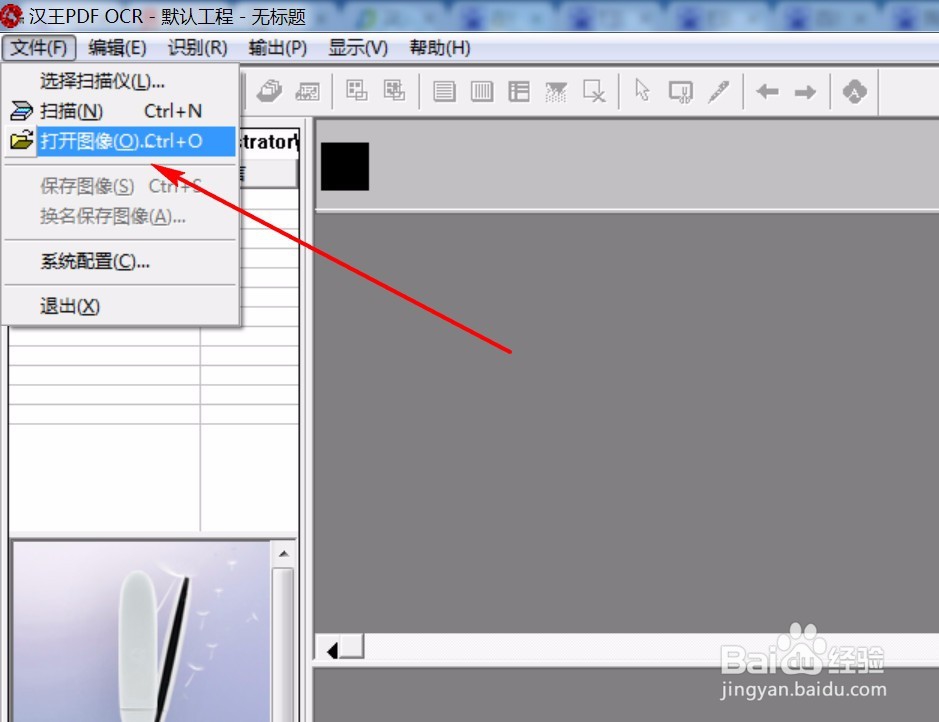
3、点击文件-打开图像,找到扫描的图片或者PDF文件,点击确定,就把文件导入到软件中了。

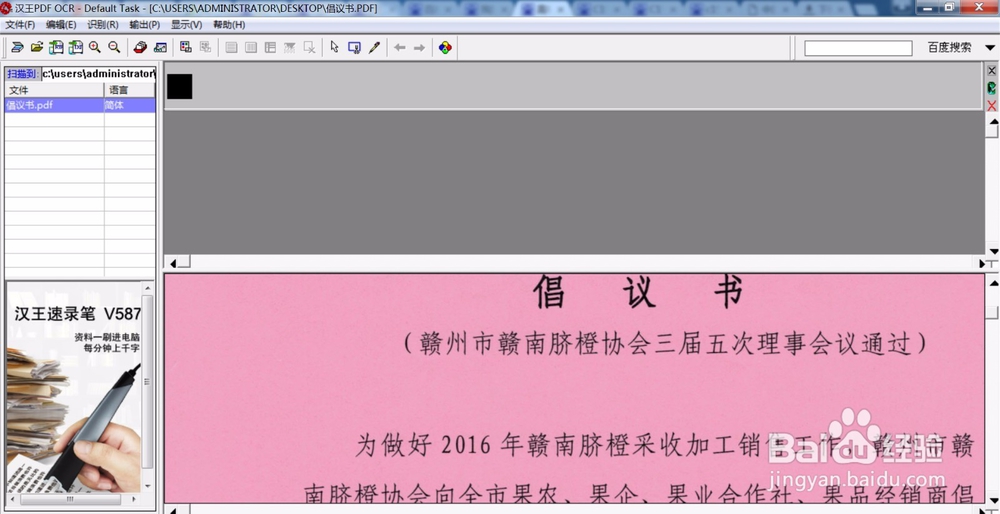
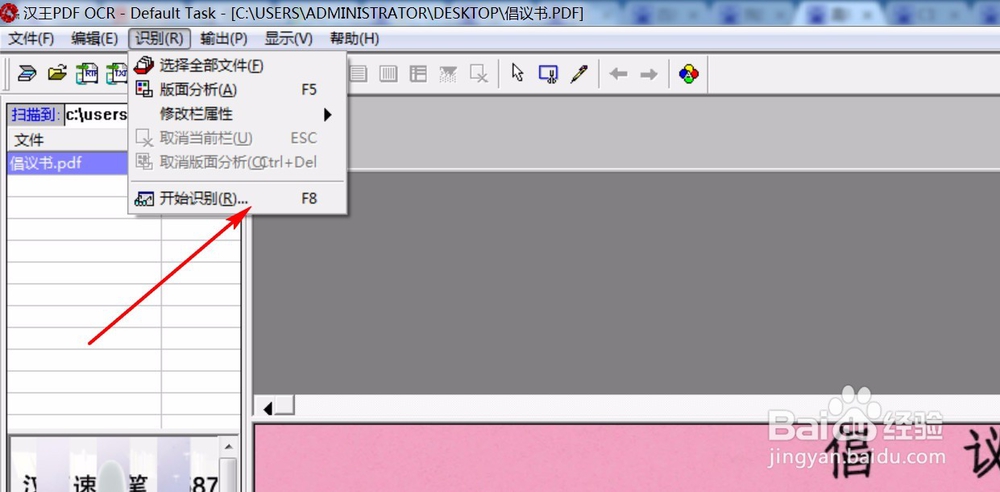
4、这一步是关键操作。点击工具栏“识别”-“开始识别”,软件就会开始自动处理图片,一般很快就完成。如图,提取出来的文字在原图的上方。
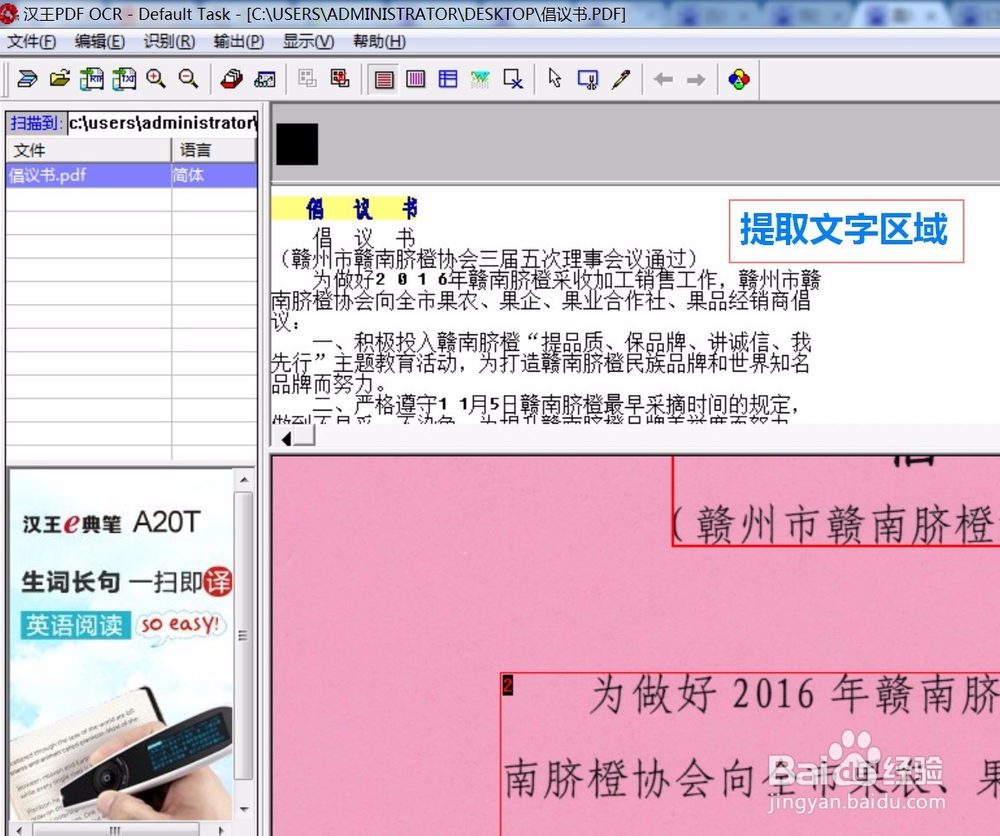
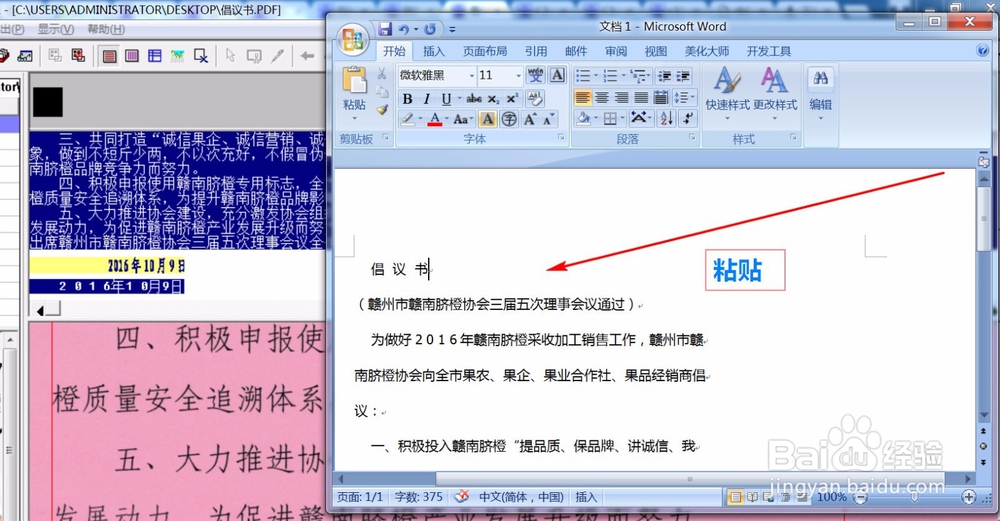
5、在提取区上点击左键,按快捷键“Ctrl+A”,就可以全部选中文字,右键复制,粘贴到Word、txt等文档中就可以了。然后再简单的编辑排版就大功告成了。
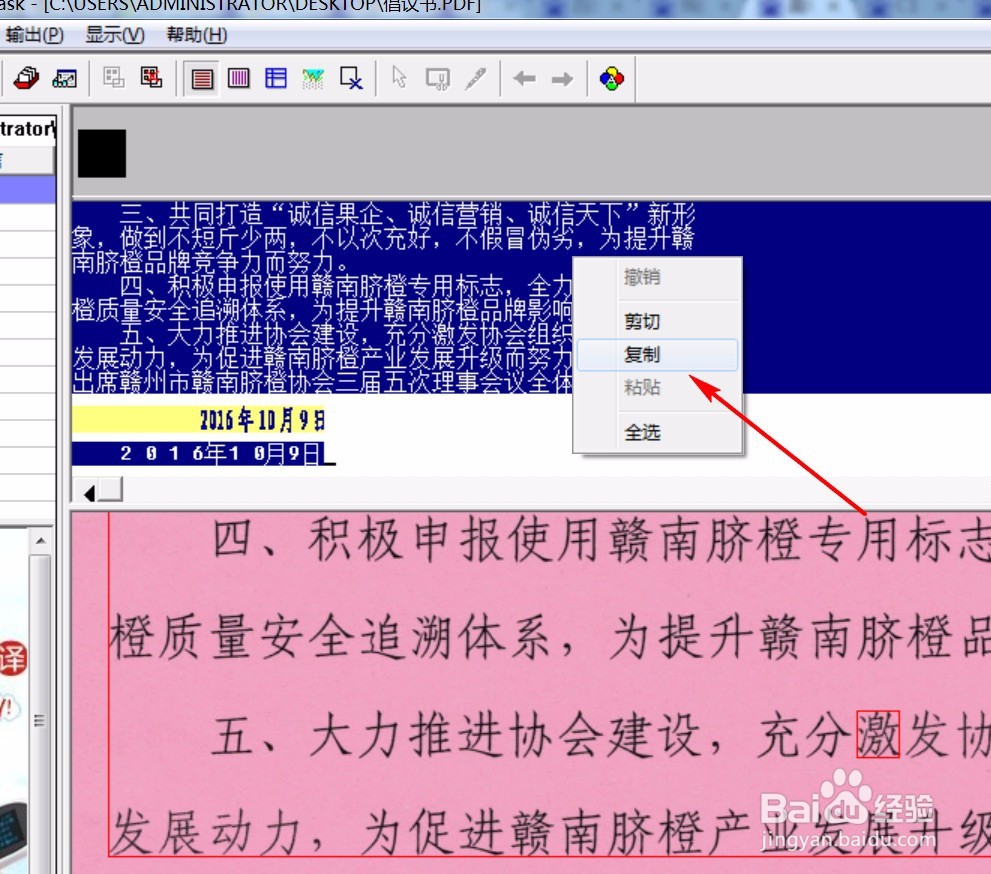
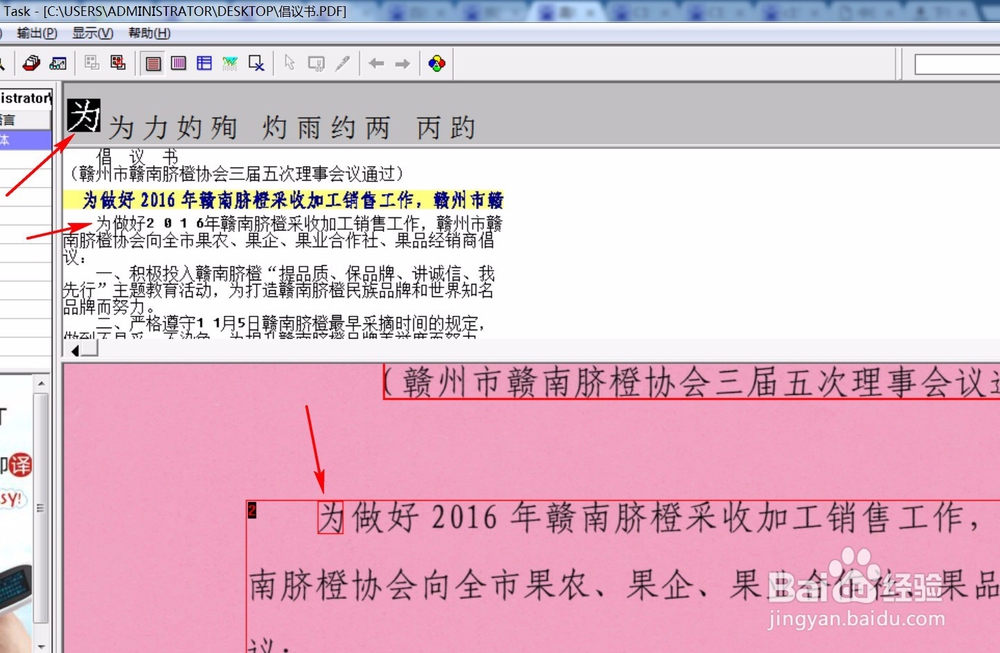
6、当然,软件也不是百分之百能够识别准确的。如果发现软件识别的不对的话,也可以手动更改,如下图,点击要更改的文字“为”,软件会提示相似的字,选择和扫描原件对应的即可。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。