机器学习——泰坦尼克号幸存者预测
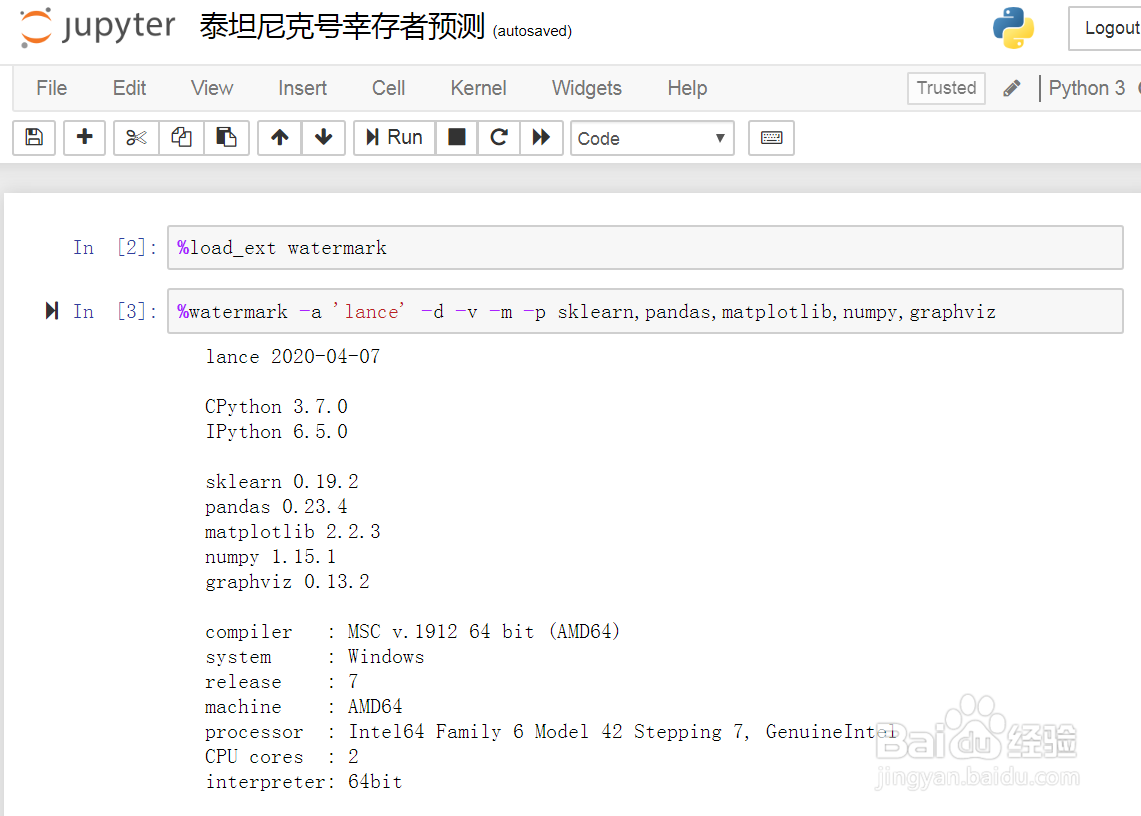
1、先展示本次实验所使用的硬件信息,及所使用的第三方库信息。
2、使用魔法命令获取相应的信息,信息如图示:
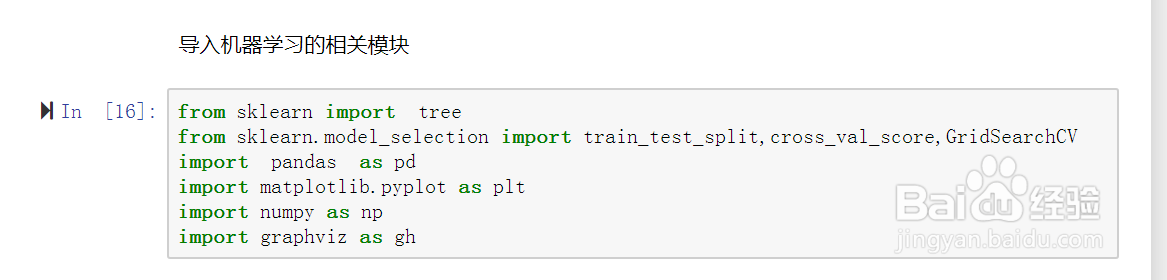
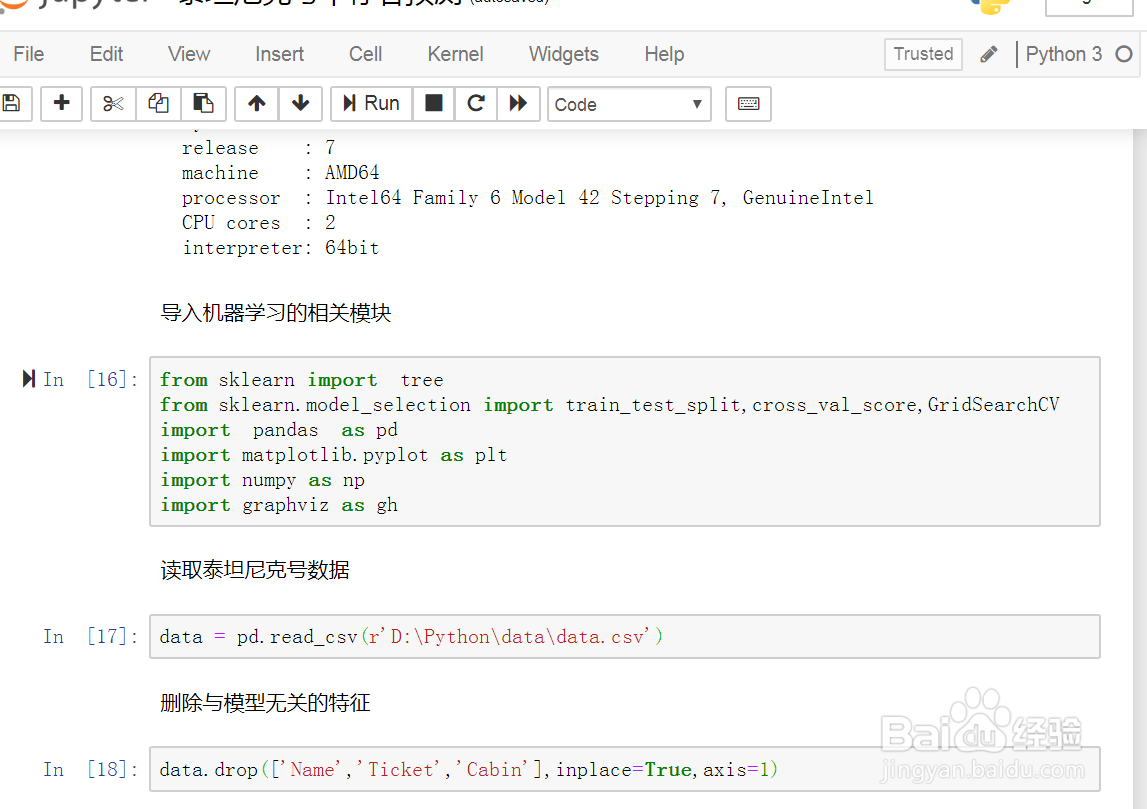
3、导入机器学习的相关模块。如图示:
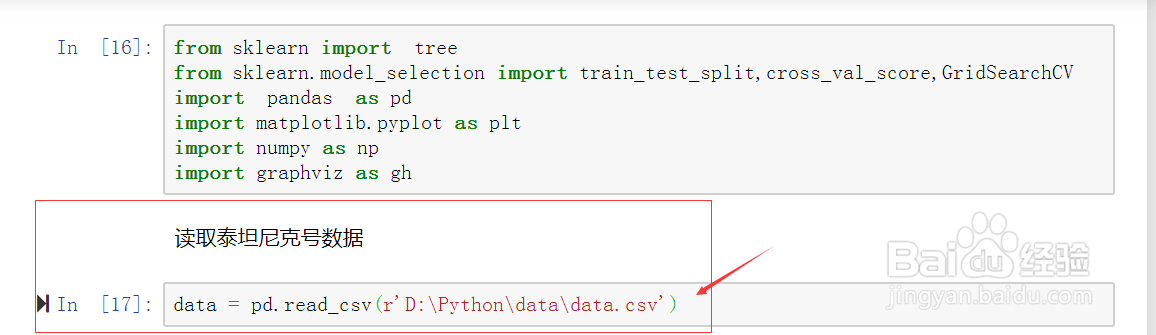
4、读取泰坦尼克号数据。如图示:
5、数据导入后,需要对数据预先处理。一下是对导入数据的预处理。
6、删除与模型无关的特征。如图示:
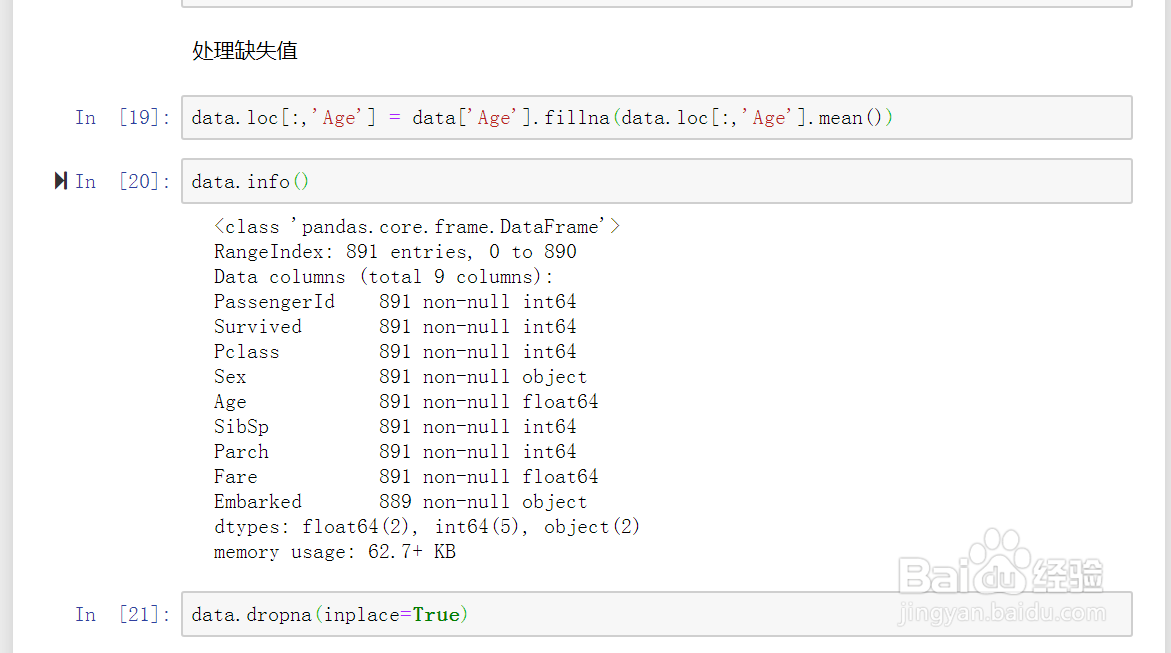
7、处理缺失值。如图示:
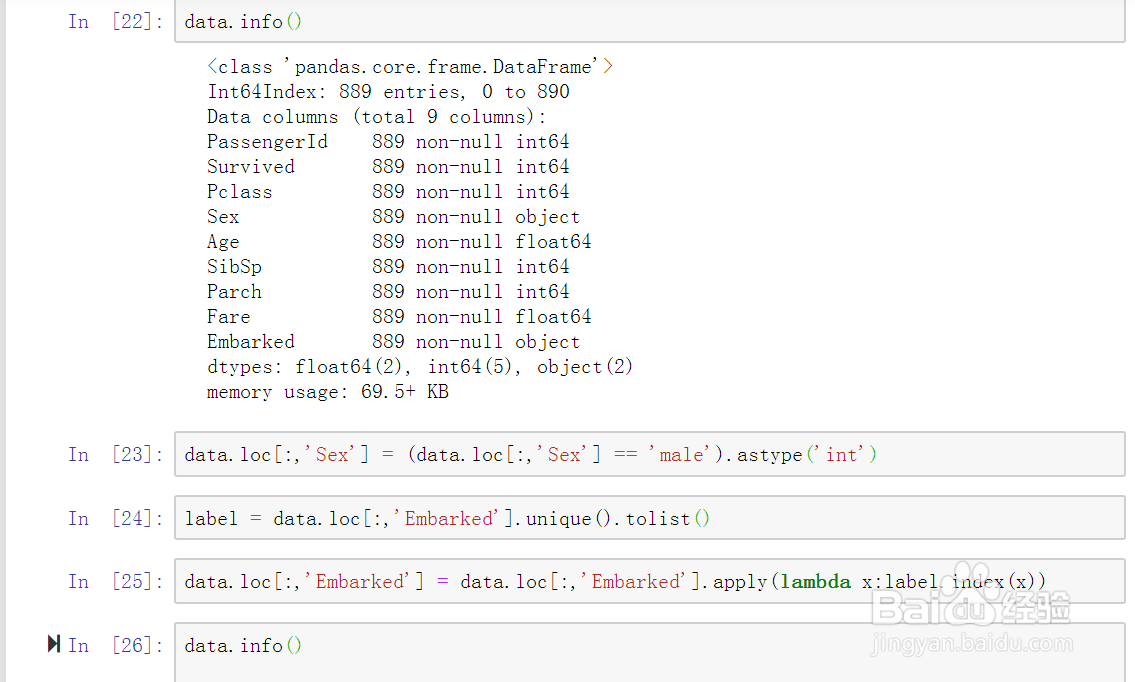
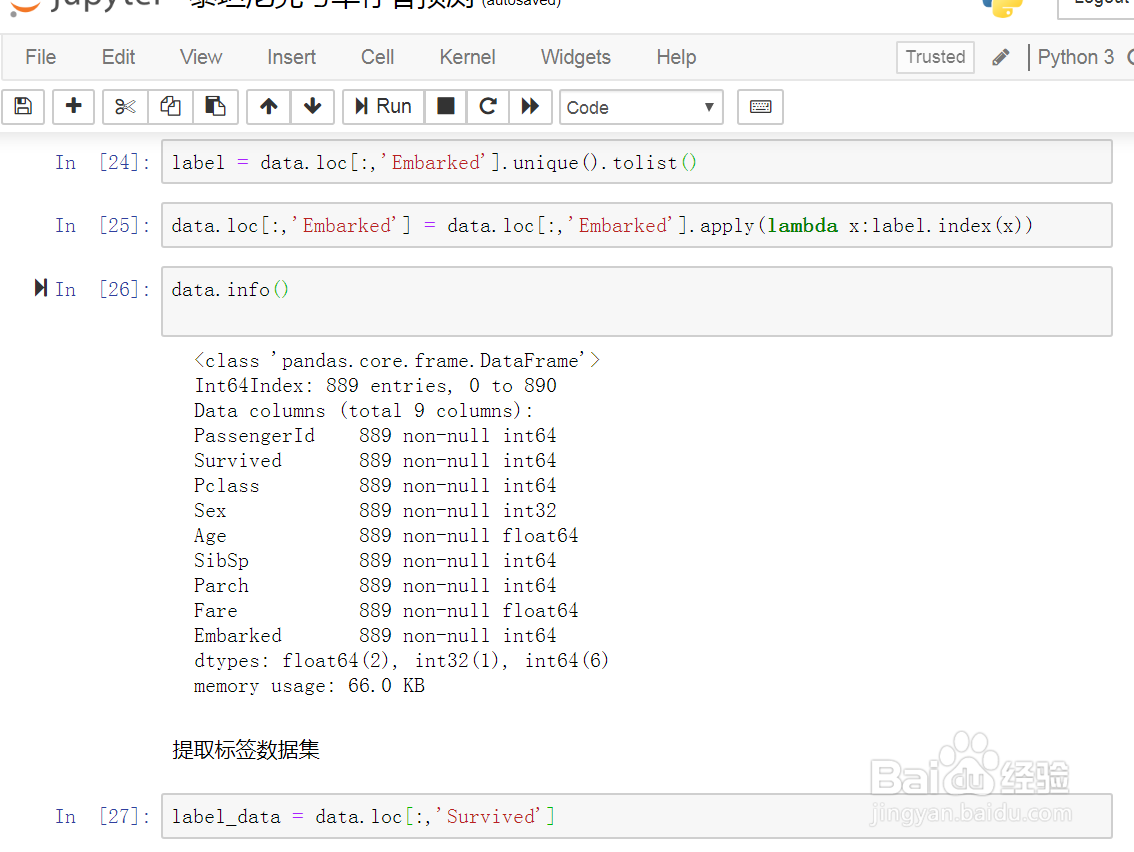
8、提取模型所需要标签数据集。如图示:
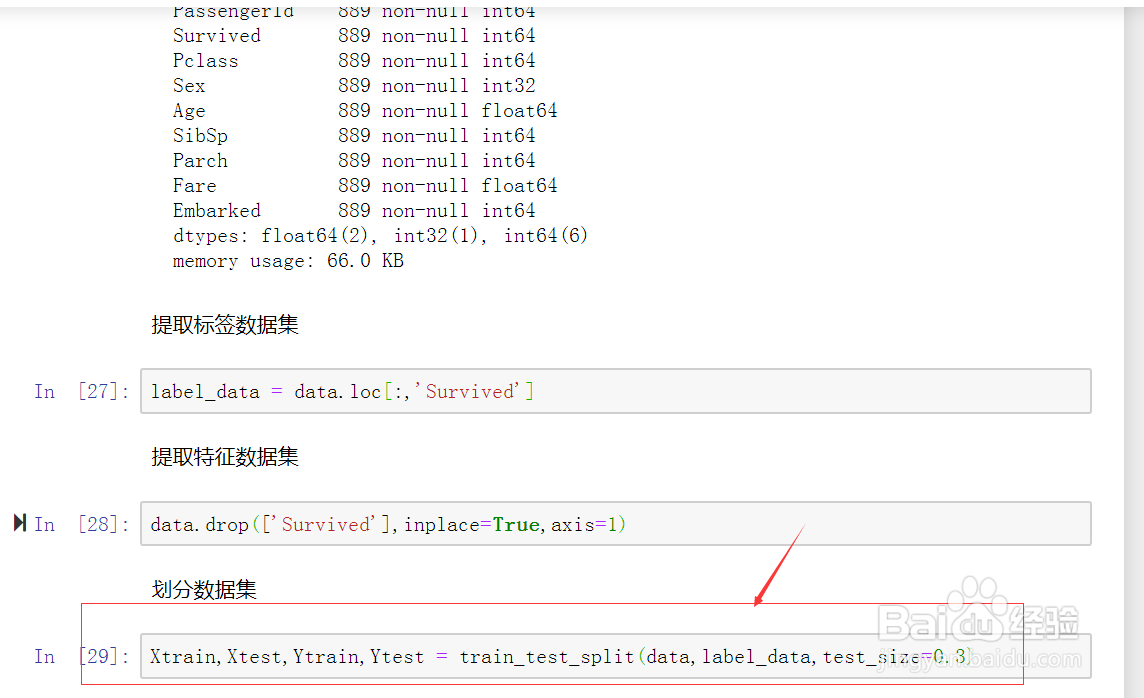
9、提取模型所需要的特征数据集。如图示:

10、数据预处理好,划分数据集,将其划分为训练集和测试集。如图示:
11、模型所需的数据准备完成后,接下来开始建立分类决策树模型。
12、使用循环遍历max_depth参数,以及使用模型的交叉验证,为绘制模型的学习曲线收集数据。
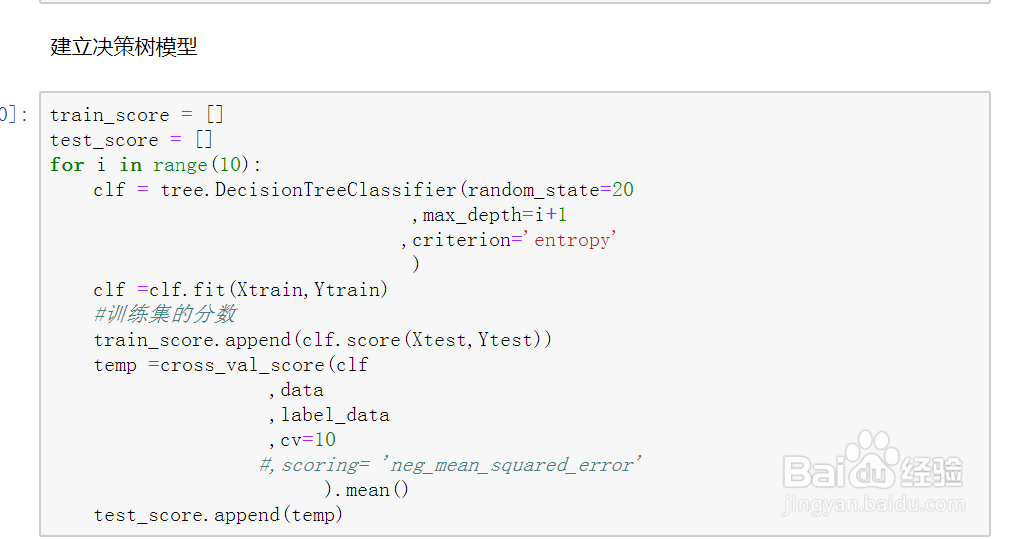
13、测试集的最佳评估。如图示:

14、训练集的最佳评估。如图示:

15、绘制模型的学习曲线。如图示:
16、学习曲线如图示:
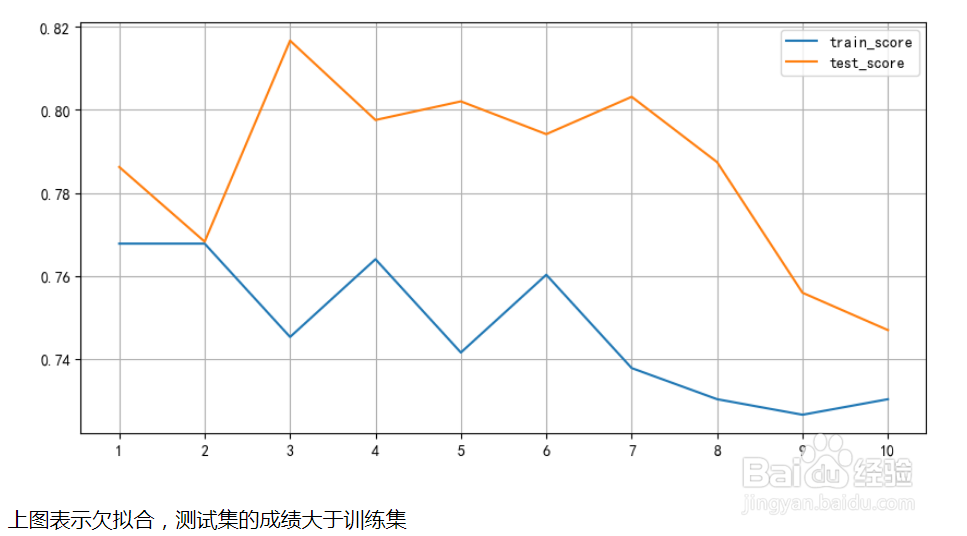
17、上图表示模型是欠拟合,因为测试集的成绩大于训练集的成绩。
18、下面介绍网格搜索,可以用网格搜索寻找最佳的参数组合。
19、接下来用网格搜索探索最佳参数。如图示:
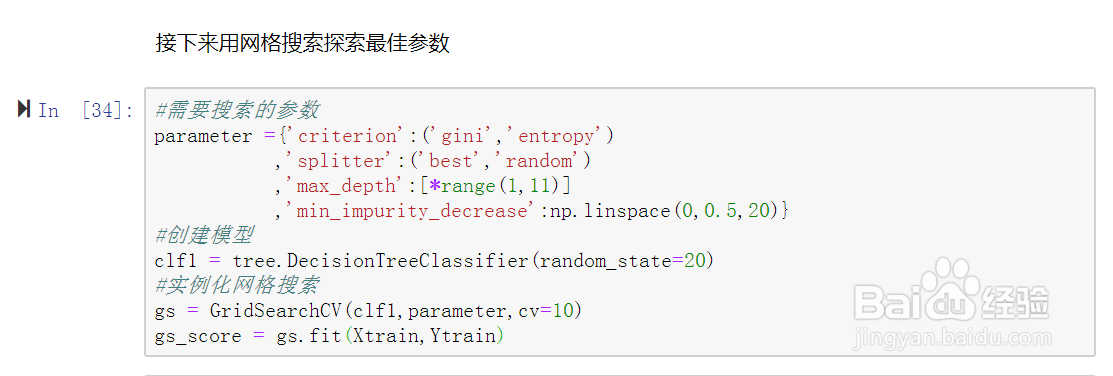
20、由于网格搜索的本质是枚举,因此执行网格搜索需要等待一些时间。
21、网格搜索完毕后,可以利用best_params_属性获取最佳的参数组合。如图示:

22、网格搜索完毕后,可以利用best_score_属性获取最佳参数的评估成绩。如图示:

23、新建一个分类树模型,将网格搜索得到的最佳参数传入模型。如图示:
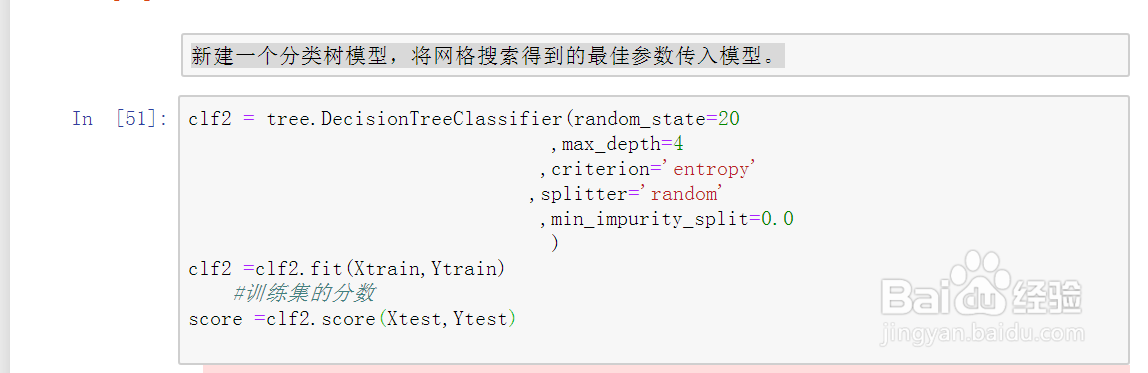
24、查看训练集的评估成绩,对比之前的评估成绩,模型的评估成绩提高了。具体如图示:
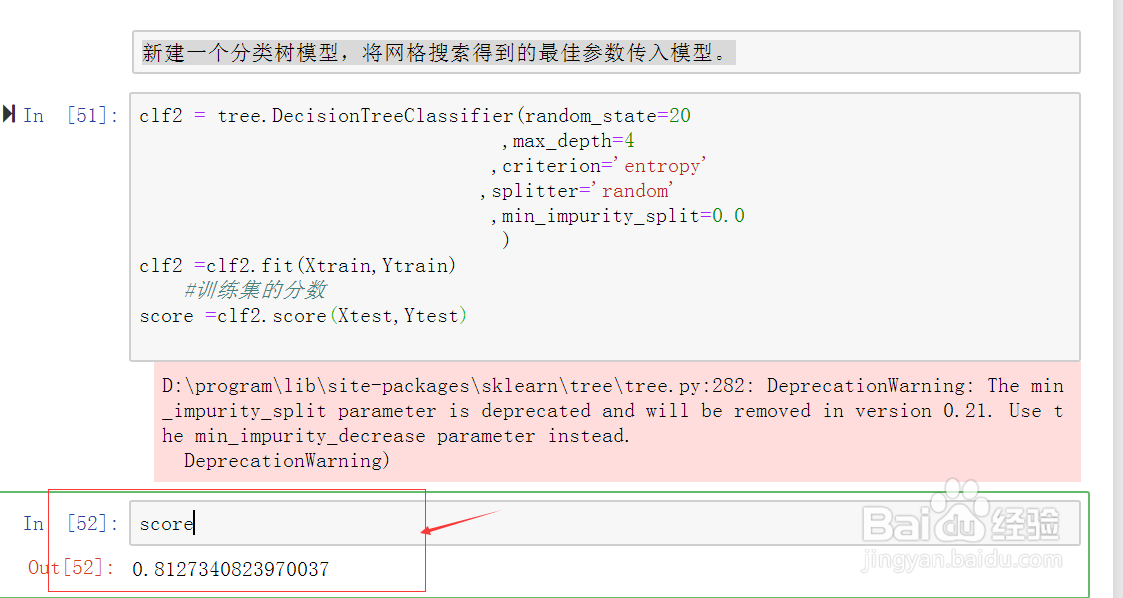

25、注意网格搜索得出的结果,并不一定都是最优的。
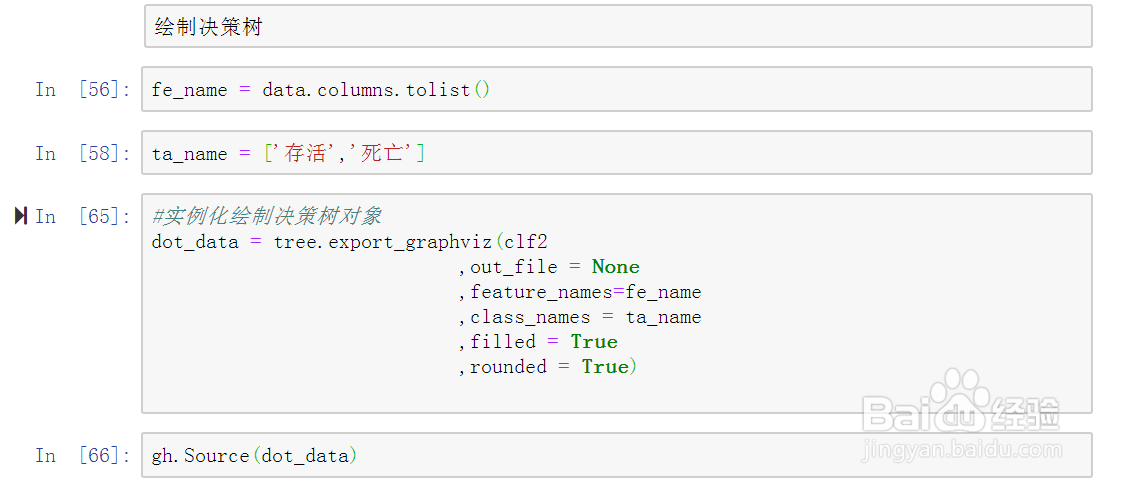
26、接下来绘制分类决策树。如图示:
27、决策树如图示:
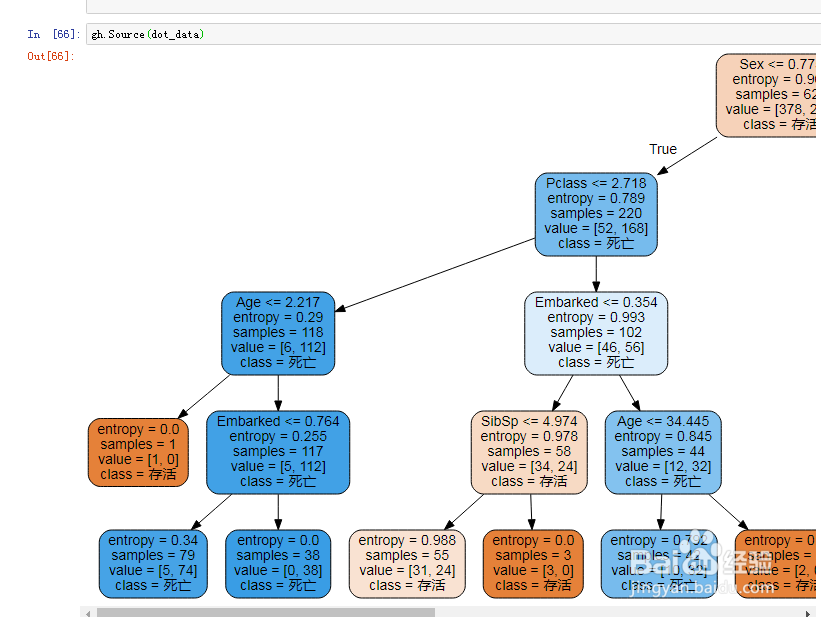
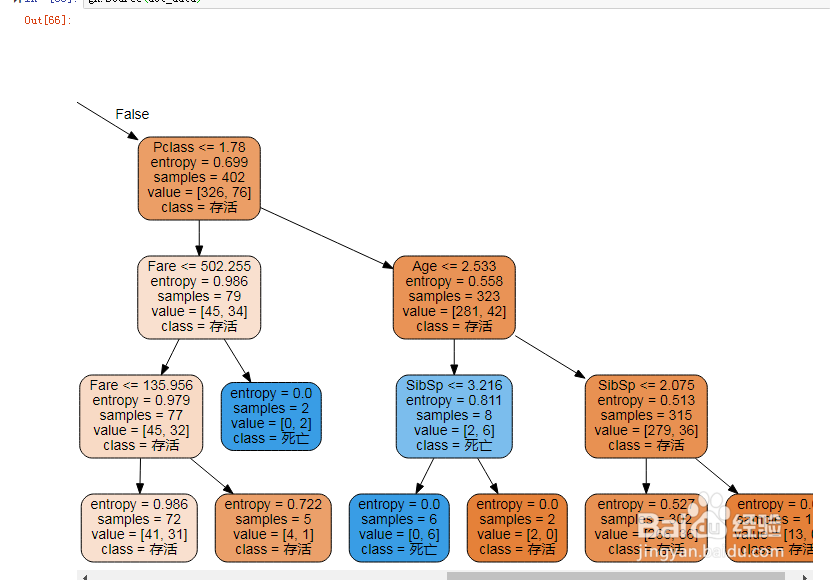
28、以上就是分类决策树在在此案例中的应用。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:79
阅读量:20
阅读量:66
阅读量:45
阅读量:23