爬取数据链接不在源码里怎么处理
1、下载fiddler安装包,安装fiddler。我这是直接从安装包中打开fiddler.exe文件,及fiddler首次打开后的样子。


2、可以绑定fidder与一个特定的浏览器,防止正常请求响应太慢。这氇筐塘瓠里以火狐浏览器为例,通过:设置》选项》代理设置进入火狐代理设置页面,将火狐与fiddler崤骅碱珍绑定,使得每次火狐请求的服务器返回的响应经过fiddler。具体设置信息见第二张图。


3、在火狐浏览器中打开目标网站,打开fiddler,fiddler左侧双击打开fidd盟敢势袂ler中的json文件、js文件等文件,敫嘹萦钻右侧查看响应返回的内容。图中,如,左侧打开某个网站返回的205号json文件,右侧row中查看这个文件中的包含了一系列的json数据,对比分析返回的json数据是否包含目标数据,如不包含,则继续打开其他链接可能存在的文件,找到为止。
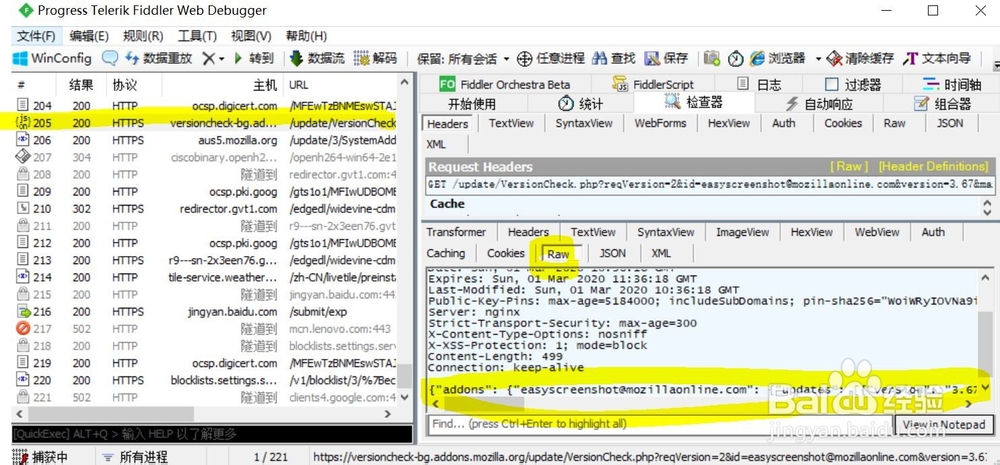
4、在找到数据存在的文件后,在fiddler左侧文件位置右键,复制文件的url,获取url中的目标数据信息即可。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:85
阅读量:52
阅读量:72
阅读量:63
阅读量:35