如何禁止爬取网页中的链接
1、首先我们创建一个robots.txt

2、根据Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接。方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。

3、在robots.txt文档中加入Disallow: *.htm,保存文件。
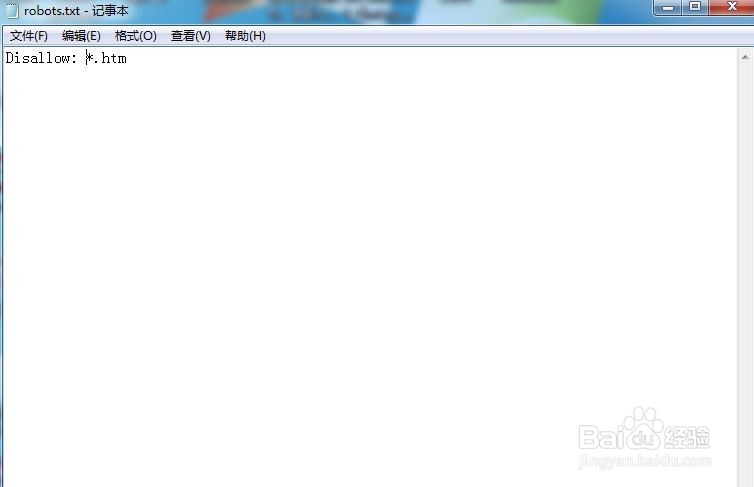
4、将保存的文件上传到网站的根目录。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。