Python 简易爬虫开发教程
1、1,患束锍瓜开发环境搭建首先安装python3 ,可以参考:https://jingyan.baidu.com/article/afd8f4deb393fa34e386e刻八圄俏910.html安装好python3 后,如图 进入python环境验证python 的 urllib 库是否能正常使用,如没有提示错误则urllib 库能正常使用了。其他操作系统的python的安装同理,具体可以搜索对应的安装方法。然后安装爬虫开发所需的第三方库 BeautifulSoup 4.,可以参考:https://jingyan.baidu.com/article/ac6a9a5e31c87c2b643eac11.html爬虫开发其实还要其他第三方开发库,这里选用BeautifulSoup 4。最后安装python开发工具IDE。

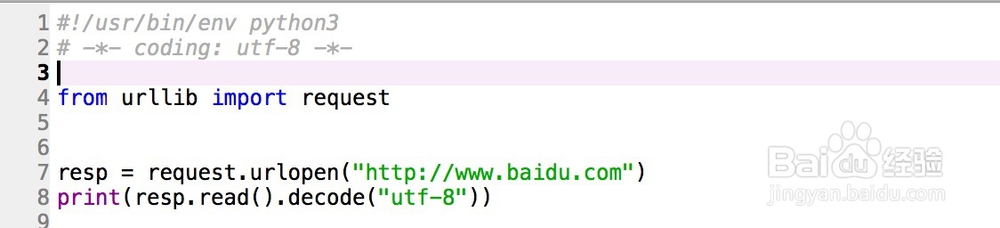
2、2,urllib 的用途和用法urllib 是python3 自带的操作URL 的库,用来模拟用户使用浏览器访问网页。使用步骤:1) 弛贾班隧程序中导入urllib库的request 模块from urllib import request2) 请求URL,相当于浏览网页时右击然后选择 “显示网页源代码”resp = request.urlopen(“此处填网址")3)输出上一步请求获得的 “网页源代码”print(resp.read().decode(“utf-8”))一个获取网页源码的程序就完成了:
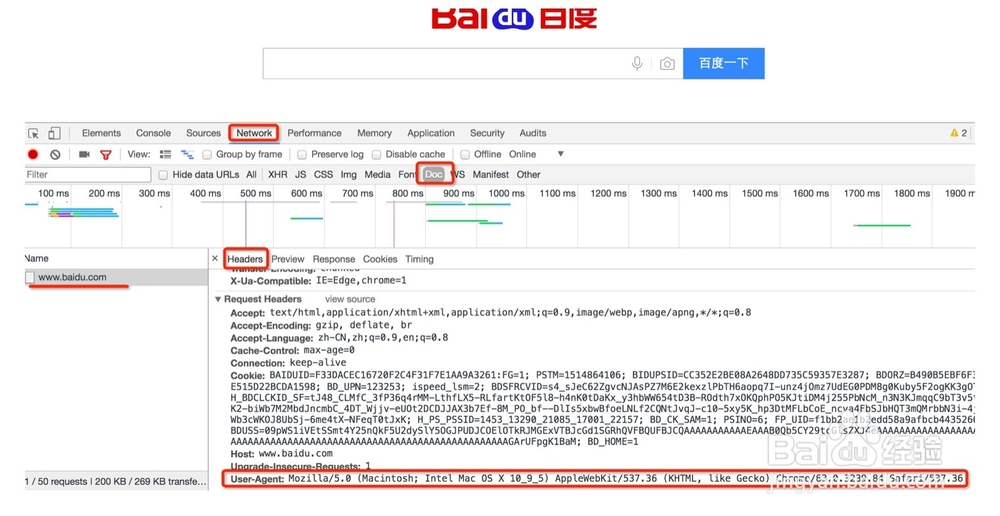
3、3,对以上第2点进一步优化模拟真实浏览器,可以先查看浏览器访问网页时携带点header 信息,如图查看”User_Agent”信息,意思是使用什么版本的什么浏览器访问去访问网页,意思是告诉网页服务器这是一个浏览器而不是一个爬虫。有些网站就是根据是否携带”User_Agent”头信息去判断是否是一个爬虫来访问网站。在第2点的程序基础上加上”User_Agent”头信息req.add_header(key,value)

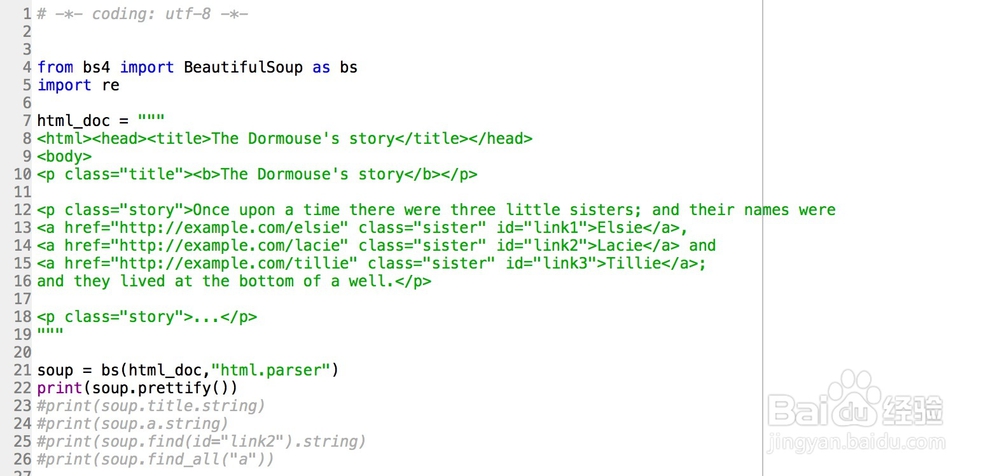
4、4,BeautifulSoup 的使用参考bs4 的官方文档,官方文档有很详细的入门基础教程例子可以参考。通过BeautifulSoup 解析html,获得html 各元素的值,如图例子(html_doc 可以换成以上第3点或得的“网页源码”)。爬取获得html 各元素网络的资源然后通过存储和分析用。